引言
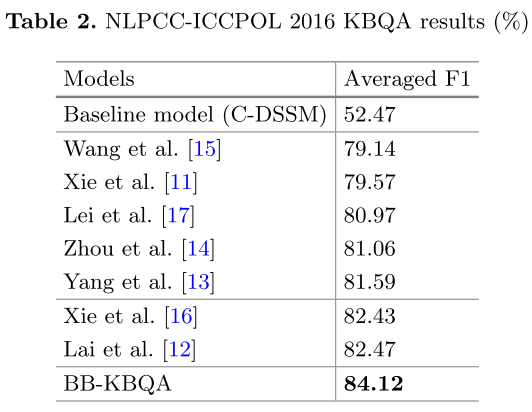
作者是在NLPCC2016的中文KBQA数据集上做的实验,该数据集中所有的问题都是一跳简单问题。
方法的基本框架包含三个部分:
- 实体链接,包括mention识别和实体消歧。识别出问题中的所有mention,然后将它们连接到KB中的实体。因为一个mention可能有多个候选实体对应,所以要消歧。
- 谓词匹配,匹配问题与KB中的候选谓词。
- 答案选择,将候选实体-谓词对排序,将top1转化为查询语句,查询KB得到答案。
介绍别人工作的部分(从实体链接部分没有过渡直接介绍了谓词匹配,有点突兀)
提出了人工特征和BiLSTM、CNN的不足之处。
于是作者使用BERT来解决上述的问题,并列出两点贡献:
- 使用的BERT-CRF和BERT-Softmax模型利用外部知识,产生问题、实体和谓词的深度语义表示
- 在数据集上取得了SOTA,可见方法的有效。
BB-KBQA模型
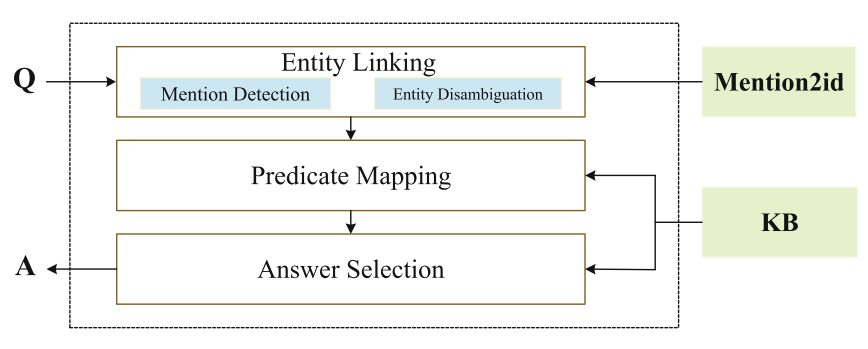
模型
首先,简介了BERT(略)。然后介绍了本文中主要使用的两个模型BERT-Softmax和BERT-CRF。
BERT-Softmax
用BERT编码输入文本序列,[CLS]位置的隐层向量,接softmax分类,学习率,epoch30。
BERT-CRF
用BERT编码输入文本序列,隐层向量H,接CRF层序列标注,学习率,epoch3。
模块
实体链接
-
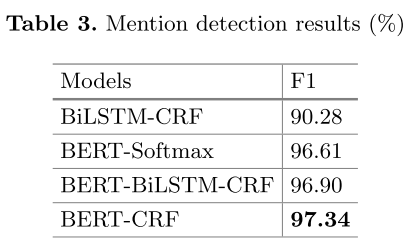
mention识别
模型
BERT-CRF,使用的是BIO标签。
-
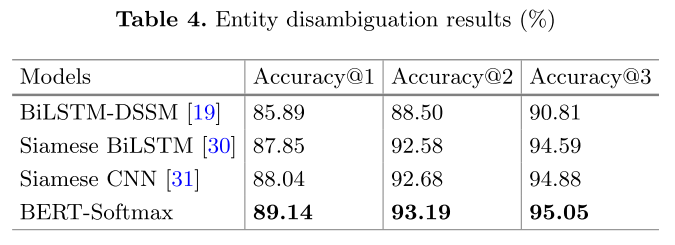
实体消歧
评测方提供了mention2id文件,能将mention映射到KB中所有可能的实体。对于每一个候选实体 ,将问题与其拼接,输入到
BERT-softmax模型中,输出的“1”标签对应的概率值即为该候选实体的得分。
谓词匹配
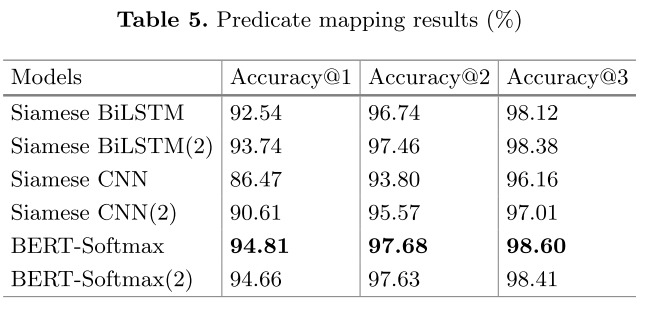
根据得到的候选实体,可以获得候选谓词集合。类似于上一步,将问题和关系词拼接输入到BERT-softmax模型中,输出的“1”标签对应的概率值即为该候选谓词的得分。
答案选择
综合实体评分和谓词评分,加权求和作为最后的实体-谓词对分数,α=0.6。
实验
数据集
以上三个子任务需要不同的数据集训练。
mention识别的数据集由作者人工标注。
实体消歧的数据集,作者收集了所有对应正确mention的实体,正确的实体作为正例,其余实体作为负例。
谓词匹配的数据集,作者手机了所有对应正确实体的谓词,正确的谓词作为正例,其余的作为负例。
结果

总结
本文提出的方法在NLPCC2016数据集上取得了SOTA。将来,作者计划在其他数据集上进行实验,并尝试实体链接和谓词匹配的联合模型。



