引言
本文作者来自中央研究院资讯科学研究所,在台湾应该是类似中科院的机构吧,不是很了解。这篇论文发表于NAACL2019(已经是去年的论文了,唉,时间过得真快)。
在组会上,为了给一些不了解、不做这个方向的同学讲清楚,我就从一些KBQA的基本概念讲起。当时也不是很熟练吧,事后写成博客应该更加凝练。
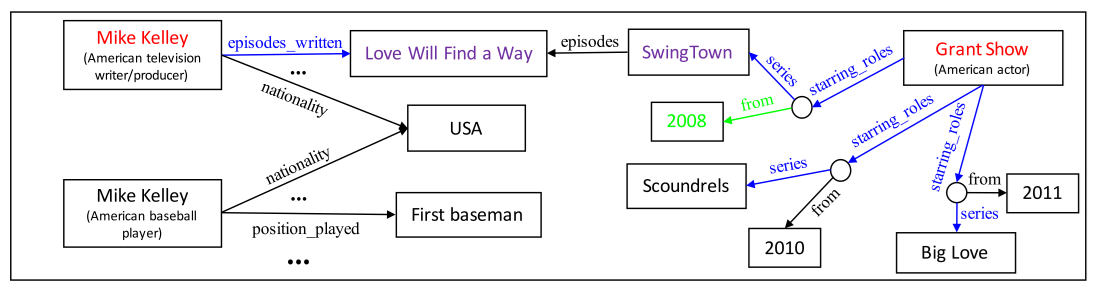
知识图谱大家应该都有所了解,里面的知识是由<head-entity, relation, tail-entity>这样的三元组形式存储的,每个实体用关系联系起来,就形成了一个图的结构,如上图所示,暂忽略图中的颜色标示。当然上图也只是知识图谱的一小部分,例如Freebase这样的大型知识图谱,里面的三元组总数达到了19亿个。
而KBQA(Knowledge-Based Question Answering ),基于知识库的问答系统便是以知识图谱作为知识来源,对于输入的自然语言的问题,理解、查询后,向用户返回从知识库中找到的答案。
问题一般分为两类,简单问题和复杂问题,例如(结合上图知识图谱):
-
简单问题:What episode was written by Mike Kelley?
回答所需三元组:<Mike Kelley, episodes_written, Love Will Find a Way>
-
复杂问题:What tv show did grant show play on in 2008?
回答所需三元组:<Grant Show, starring_roles, CVT>, <CVT, from, 2008>, <CVT, series, SwingTown>
如果不考虑基于翻译的方法,即序列到序列直接由问题得到查询语句,通常情况下,可以把KBQA划分成两个子任务来做,实体链接Entity linking和Relation Detection/Extraction。
-
实体链接。一般来说,问题中都会有主题实体的提及
topic entity mention,比如上述问题中的Mike Kelley,这是我们切入问题的关键。实体链接这一步便是找到这样的一个topic entity。这一步主要完成两个任务:- 实体提及的识别
Mention detection。这部分我所了解的方法有,将知识库中所有的实体形成一个词典,用来匹配问题中的子字符串,得到mention进而得到候选实体;或者使用序列标注的模型,例如BERT-CRF来对问题文本标注,获取mention,然后再匹配知识库中的实体。因为我做过的任务中,评测方都会给一个mention2entity的映射文件,所以这一步会被简化,我了解也不具体。 - 候选实体消歧
Candidate disambiguation。一个问题中我们通过各种方法识别出mention,mention可能不止一个,mention对应的知识库中的实体通常有多个,这一步实际上是对候选实体的一个筛选的过程。以上图知识图谱为例,Mike Kelly在知识库中有两个,一个是编剧,另外一个是棒球运动员,与这个问题相关的应该是编剧的Mike Kelly。所以我们可以人工选择一些特征进行筛选,或者结合知识库中的实体相连的关系进行筛选。
这两个子任务都有单独的研究,像实体链接这部分,Dbpedia有
DBpedia Spotlight,Freebase有S-MART这样的实体链接工具,只研究关系检测这部分的研究者,通常使用实体链接工具得到的结果的基础上,进行下一步的研究。 - 实体提及的识别
-
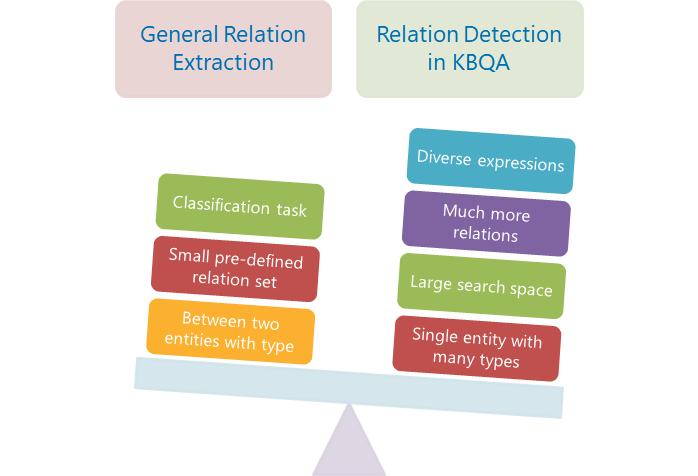
关系检测。本文中使用的词是Extraction,因为会和广义的关系抽取搞混,所以我更倾向于使用Detection这个词。一些只做关系检测的论文中,往往会与广义的关系抽取进行比较。广义的关系抽取是一个分类任务,会预先定义需要抽取的关系类型,通常不超过100种,一般从文档或者句子中抽取两个已知类型的实体之间的关系。而KBQA中的关系检测,由于知识库中包含的关系种类非常之多,有监督学习时训练集无法包含所有的关系,测试集中可能出现unseen的关系;当问题复杂需要多跳关系路径解答时,组合非常多,搜索空间巨大;并且问题中通常只包含一个实体,这个实体在知识库中的类型也会有很多,所以不能使用广义上的关系抽取来做。
早期研究使用语义解析的方法,解析出句子中的谓词,和知识库中的关系进行匹配。深度学习出现之后,通常使用匹配模型将问题和关系路径进行匹配,用相似度作为关系路径的得分进行排序。关系的向量表示可以使用预训练的网络向量表示方法,如TransE,或者将关系名作为有意义的序列进行embedding。
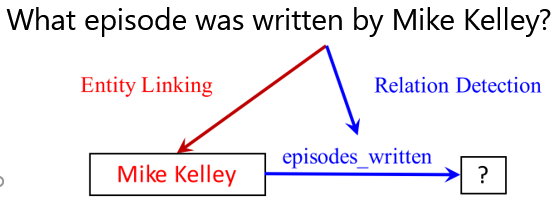
经过上述两个步骤,我们解决上述问题的过程就如下图所示。
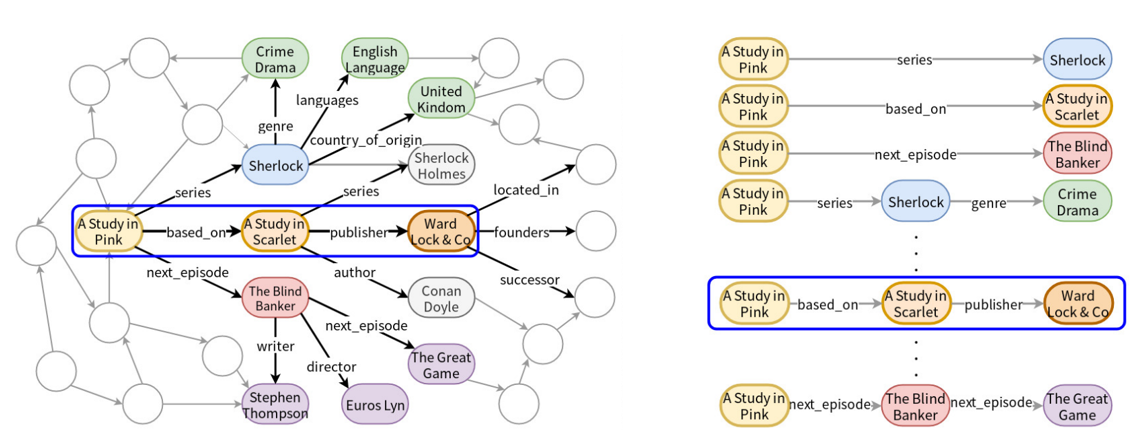
我们再来考虑这样一个问题:“Who published the novel adapted into A Study in Pink ?”。由于本文提出的框架是relation detection步骤的,所以假设我们已知正确的topic entity:<A Study in Pink>。然后我们会以该实体为起点,从知识库中获取两跳范围内的关系路径与问题进行匹配(常用的数据集通常用一跳或两跳关系即可回答)。但是,现实应用中我们无法对问题用一个最大跳数进行限定,而且随着跳数的增多,关系的组合数目会以指数级增长。基于这些问题,作者提出了一个框架,不设定最大的跳数,将多跳的路径匹配分解成了两个子任务:单跳关系检测和比较式的终止决策。
作者列出了以下几点贡献:
- UHop框架中不需要设定最大跳数,让模型自己决定什么时候停止。
- UHop将搜索空间的复杂度从指数级降到了多项式级。
- UHop框架促进了SOTA模型的利用。
相关工作
匹配模型通常使用孪生神经网络这样的结构,将不同输入通过同样的网络编码到相同的向量空间来计算相似度。损失函数可以使用pointwise的交叉熵和MSe,pairwise的Hinge loss。接下来介绍本文中框架所使用的SOTA模型和用来对比的baseline工作。
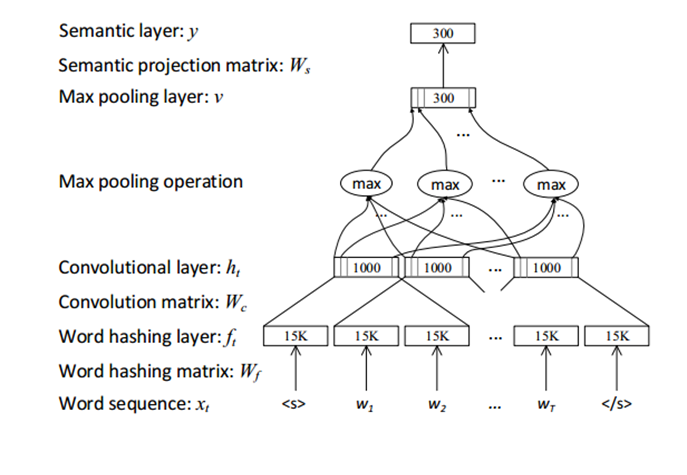
BiCNN 2015
比较早期的工作,输入部分使用word hashing的trick,以who这个单词为例,先在首尾加上边界符,变成#who#,然后分解为tri-grams,用#-w-h,w-h-o,h-o-#表示who这个单词,向量表示便是上面三个tri-grams的向量的拼接。这样做可以极大减少词表的大小。
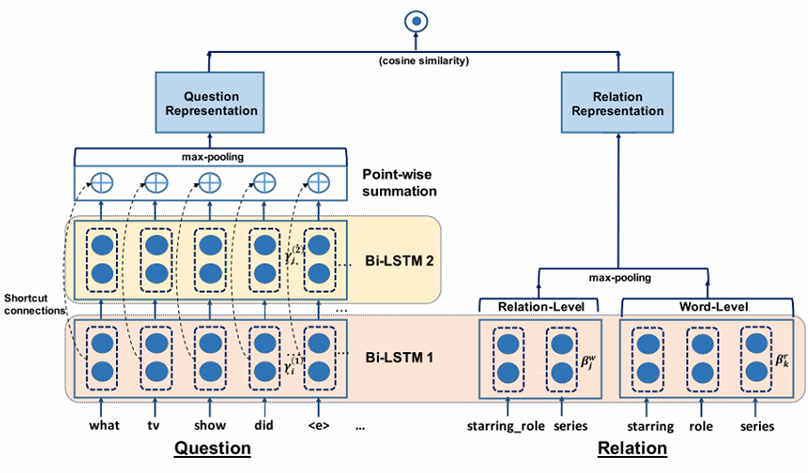
HR-BiLSTM 2017
问题表示部分使用了两层BilSTM的残差连接,关系表示部分既使用了完整的关系序列和拆分后的词序列。
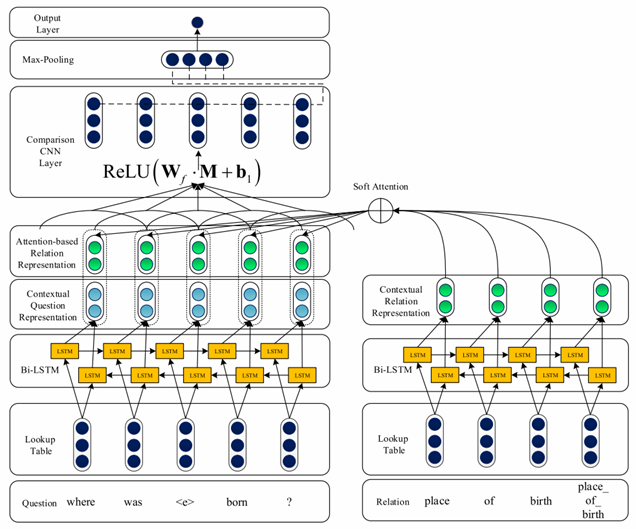
ABWIM 2018
针对一些模型在问题和关系表示向量做了pooling操作后进行匹配,可能会导致信息的损失的问题,该工作在模型的较底层使用attention机制进行交互,再使用CNN进行分类。
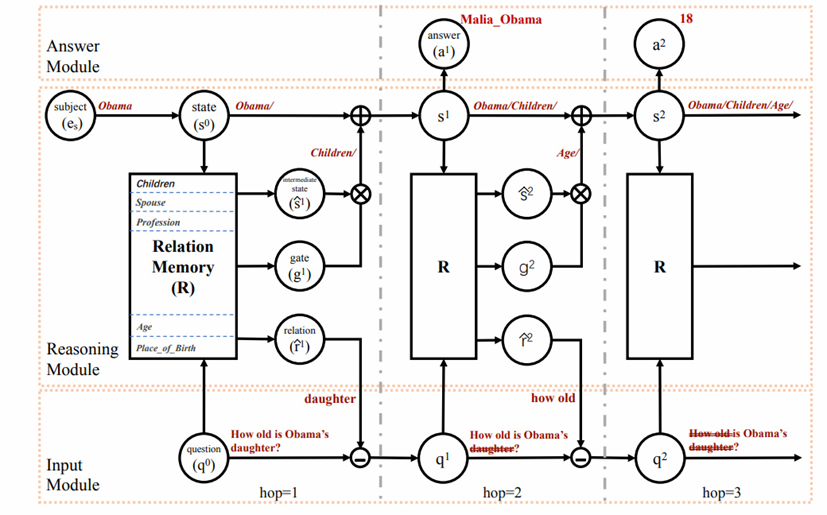
IRN 2018
该工作和作者的十分相似,分为输入模块,推理模块和回答模块。推理模块根据当前状态从候选关系中选择得分最高的关系,进入下一状态,并不再考虑问题中与该关系相关的文本。作者在relation memory中加入了表示终止的关系Terminal,如果推理模块选择了该关系,则停止进入下一状态,回答结束。
方法

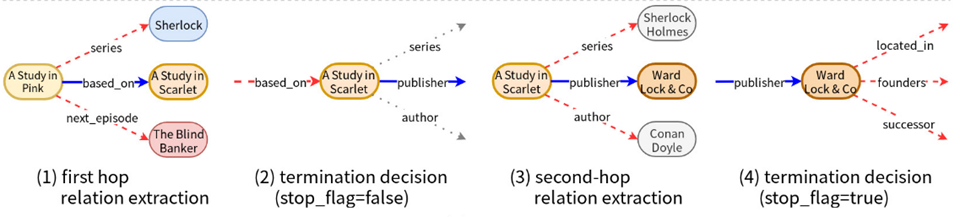
Single Hop Relation Extraction
该模块就是对与当前实体相连接的所有关系进行打分,选出得分最高的关系,转移到下一个实体(状态)。模型选择为HR-BiLSTM或ABWIM,损失函数为
Comparative Termination Decision
该模块判断与当前实体相连的下一跳的所有关系的得分是否大于上一模块抽取出的关系的得分,大于则继续循环,否则停止循环回答结束。模型结构与上一模块相同。两种情况的损失函数分别为
Dynamic Question Representation
经过每一跳的选择,已经抽取出的关系对应问题中的文本变得不再重要。随着算法的执行,问题所包含的信息应该越来越少。这样就能避免关系链形成环路,循环无法停止的情况。对于有attention的模型和没有attention的模型,作者分别采用如下的方法动态更新问题的表示
Jointly Trained Subtasks
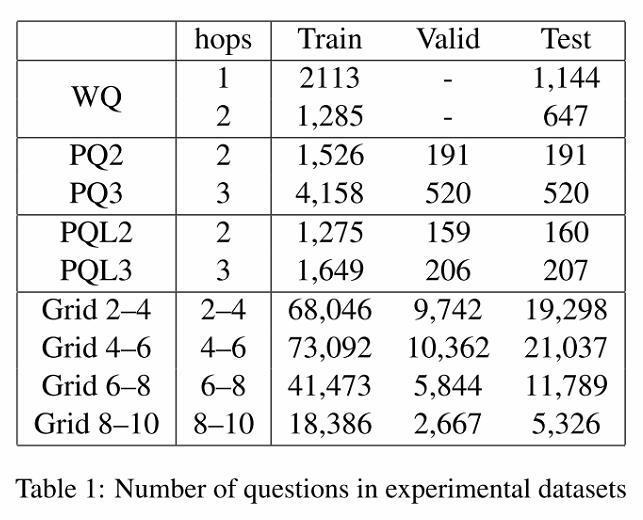
Datasets
WebQSP
WebQuestion的语义标注版本,包含一跳和两跳问题,两跳问题占大约40%。知识库为Freebase。
PathQuestion
包含普通版本和large版本,large版本的知识库更大,关系类型更多。每个版本又包含两跳和三跳的数据集,合计四种:PQ2,PQ3,PQL2,PQL3。知识库使用Freebase的子集。
Grid World
输入为一个起始结点(topic entity),一系列的导航指令(question),和一个16x16的网格。该任务目的是每一步遵循指令,最后到达目的地。知识库中包含的三元组都是表示方位的,如<(4, 1), South, (5, 1)>。指令长度最多可达10。但是每一步的关系类型只有8种(8个方向)。
Experiments
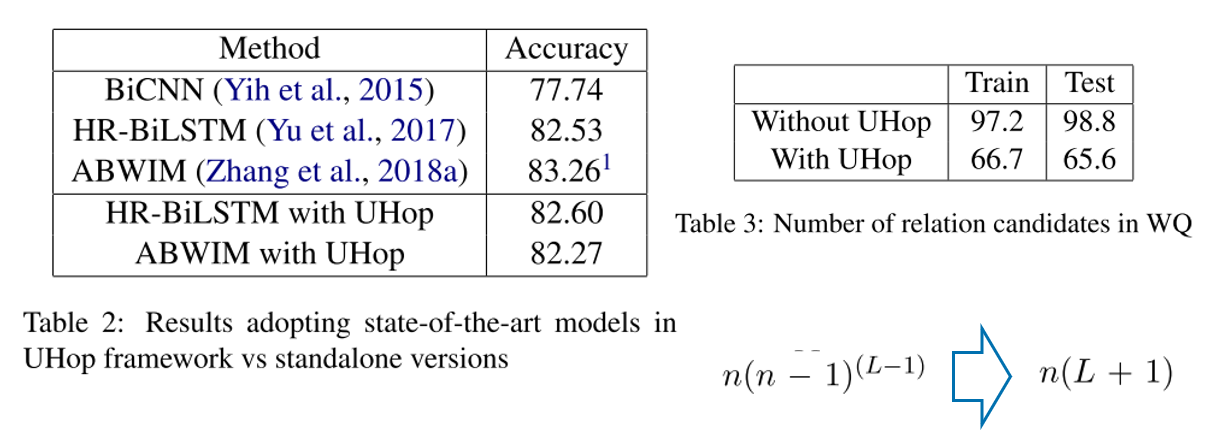
WQ
作者取得了与SOTA模型可比的效果,并且减小了搜索空间。
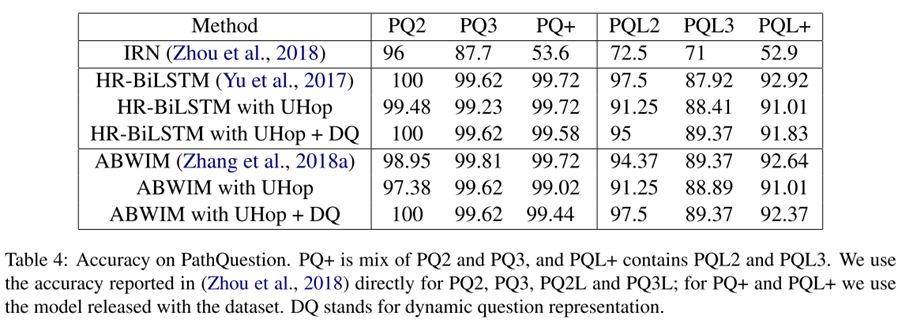
PathQuestion
由于PQ的问题是由模板和同义词替换生成的,使用的知识库的大小有限,关系类型较少,所以准确率可以达到100%。
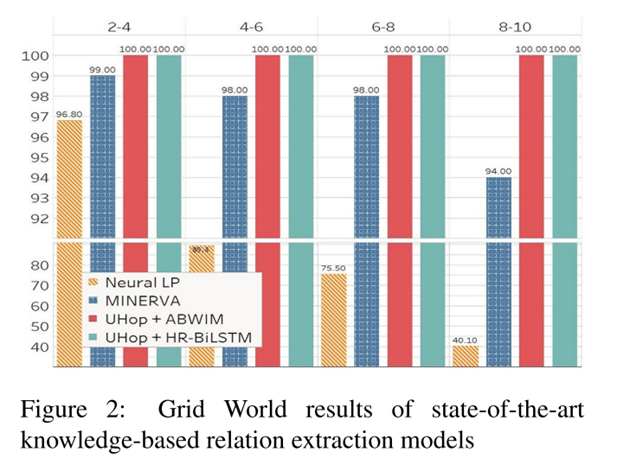
Grid World
baseline方法没有具体了解,由于关系类型只有八种,所以也可以达到100%的准确率。
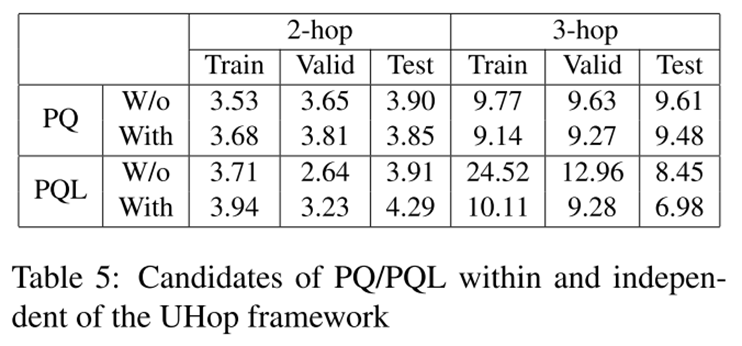
Trained on 3-hop, Tested on 2-hop
作者为了验证框架是否可以在正确的位置停止,在PQL3上训练,在PQL2上测试的结果如图。

总结
- 本文提出的框架可以减小搜索空间。
- 该框架可以应付一些长问题,在小知识库关系类型较少的任务上也有较好表现。
- 动态的问题表示有所帮助。
- 该框架使用的是贪婪搜索的思想,将来探索beam search是否能提高准确率。
参考文献
- 《UHop An Unrestricted-Hop Relation Extraction Framework for Knowledge-Based Question Answering》
- Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao. 2015. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings ofthe 53rd Annual Meeting of the Association for Computational Lin- guistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), volume 1, pages 1321–1331.
- Mo Yu, Wenpeng Yin, Kazi Saidul Hasan, C´ıcero Nogueira dos Santos, Bing Xiang, and Bowen Zhou. 2017. Improved neural relation detection for knowledge base question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pages 571–581.
- Hongzhi Zhang, Guandong Xu, Xiao Liang, Tinglei Huang, and Kun Fu. 2018a. An attention-based word-level interaction model: Relation detection for knowledge base question answering. CoRR, abs/1801.09893.
- Mantong Zhou, Minlie Huang, and Xiaoyan Zhu. 2018. An interpretable reasoning network for multi- relation question answering. In Proceedings ofthe 27th International Conference on Computational Linguistics, COLING 2018, Santa Fe, New Mexico, USA, August 20-26, 2018, pages 2010–2022.
本人水平有限,仍在学习中,如有错误或不到位的地方,欢迎在评论区指正~



