任务简介
任务名称: 平安医疗科技疾病问答迁移学习比赛
本次评测任务的主要目标是针对中文的疾病问答数据,进行病种间的迁移学习。具体而言,给定来自5个不同病种的问句对,要求判定两个句子语义是否相同或者相近。所有语料来自互联网上患者真实的问题,并经过了筛选和人工的意图匹配标注。
示例
问句1:糖尿病吃什么?
问句2:糖尿病的食谱?
label:1
问句1:乙肝小三阳的危害?
问句2:乙肝大三阳的危害?
label:0
数据集:
| dataset\disease | diabetes | hypertension | hepatitis | aids | breast cancer | total |
|---|---|---|---|---|---|---|
| train | 10000 | 25000 | 2500 | 2500 | 2500 | 20000 |
| dev | 2000 | 2000 | 2000 | 2000 | 2000 | 10000 |
| test | 9965 | 9968 | 9996 | 10030 | 10041 | 50000 |
其中正负例均衡,且每一类疾病的正负例数目相等
数据样例:

类似比赛:
- Kaggle Quora
- 天池 CIKM
- 蚂蚁金服
- 第三届魔镜杯
- CCKS 2018 微众银行智能客服问句匹配大赛
- CHIP 2018 task2
数据预处理
原始数据存在以下特点:
-
数据为自然语言问句,并且标注了问题对是关于哪一种疾病,即两个问句一定是关于同种疾病的。
-
原始数据中正负例比例均衡
-
训练集和验证集的问题几乎没有交集
-
原始数据存在标注错误
我们对原始语料进行了如下预处理:
- 由于问句中存在一些敏感词的拼音缩写表达,特别是在艾滋病类别的问题中较多,所以我们人工浏览了大部分的数据,整理了这些拼音缩写表达的对应关系,还原到了自然语言词汇。
- 高血压类问题中常出现“高血压145195”,我们对于这样的格式统一处理成了“高血压195,低血压145”。
- “尿蛋白中有x个加号/尿蛋白x+”这类表达,统一成了“尿蛋白高/偏高”。
- 对于“空腹血糖+数字”和“餐后血糖+数字”,我们也统一处理成了高中低三种标准。
- 对问句中的城市名统一去除。
- 建立停用词表,对“请问一下”,“你好医生”这类的词进行了去除
- 最后对问句中的标点符号进行了统一处理。
数据增强
目前常用的文本数据增强方法有:
-
同义词替换,去停用词。
-
随机插入,随机删除
-
随机打乱句子的顺序(对不注重语义信息的文本可能有用)。
-
随机Mask掉原始文本中的某些词。
-
回译-回翻译:指的是将目标语言翻译成另外一种语言再翻译回来的一种方法。
在最近阅读的《Distilling Task-Specific Knowledge from BERT into Simple Neural Networks》一文中,作者为知识蒸馏做了数据增强,采用了下面三种方式:
Masking。
POS-guided word replacement。词性引导的词语替换。以一定的概率用相同词性的词替换句子中的某个词。新词的选择服从原始语料中各词性标签的分布。
N-gram sampling。以一定的概率采样句子中的n个词,n从1-5中随机选出。这条规则相当于丢弃掉除此以外的其他词语,是一种更强势的masking形式。
针对该问句相似度任务,还可以使用传递闭包扩充数据量,即:
A与B相似,B与C相似,则可推出A与C相似。
A与B相似,B与C不相似,则可推出A与C不相似。
但由于我们认为训练集标注不准确,推出的相似关系可能会带来更大干扰,所以仅推出了传递闭包,没有实际应用。
除此之外,我们还到医学问答网站的检索系统输入数据集中的问题,爬取了这几类疾病的相似问题,扩充数据量。
整体框架
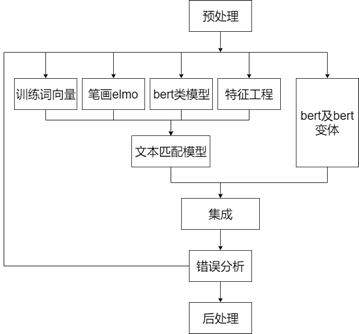
特征工程
这部分我们沿用了去年岳师兄的工作,包含特征如下:
- 以下的token分别包含(char和word)
- common_token:句子对共享token的数目,句子对token的jaccard系数,句子对共享token idf 加权得分,句子对共享token占原句的比例
- embedding_dis:句子对token的wmd距离,句子对用向量表示后的各种距离
- expand_embeddings_distance:将给定的数据分别利用gensim word2vec 和 Glove 训练的词向量,特征同上
- fuzzy_wuzzy:句子对token的fuzzywuzzy
- long_common_string:最长公共子串
- powerful_token
- 重点区分词onehot 特征。
- 比如某个token至少在20个句子对两边都出现,且为标签正确的比例>=0.9, 认为其为高度相关词
- 比如某个token至少在20个句子对中的一侧出现,且为标签错误的比例>=0.9, 认为其为高度相关词
- token_count:统计特征,句子token数目,句子去重token数,二者的比以及差值。
- 句子对tfidf和one hot 向量化的相似度计算交互特征
- 句子对向量化利用PCA降维的相似度计算交互特征
另外我们还使用了数据集中的问题属于的疾病类别和问句的词性信息作为特征。
字词向量训练
文本来源:
- 已有的生物医学文献摘要(实验室已有)
- 医学问答网站的问题:39问医生、快速问医生、寻医问药网有问必答、春雨医生、飞华健康网等(岳师兄提供+自己整理,不需要爬新的了)
使用的工具是gensim的word2vec和fasttext。
另外还使用了罗师兄的使用生物医学文摘训练的ELMo向量。
预训练模型
目前存在很多公开的通用领域类的bert模型,我们使用了:
- bert/bert-large
- bert-wwm
- Roberta
- xlnet
- 百度的ERNIE
我们主要采用了两种方式使用bert:将bert编码的问句字or词向量作为特征;在领域限定的任务上微调。微调可以参考这篇论文,《How to Fine-Tune BERT for Text Classification?》。它提出了三种方式,如下图所示:
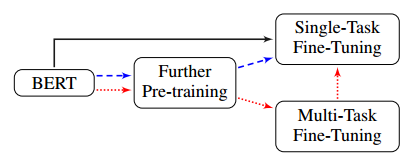
黑线:直接使用单个目标任务微调bert
蓝色虚线:使用目标领域的数据进一步预训练后,再使用单个目标任务微调bert
红色虚线:使用目标领域的数据进一步预训练后,在多个任务上微调bert,再在单任务上微调
模型集成
多个模型的效果往往强于单个模型。模型集成的方法可以是简单的加权平均,投票,或者是复杂一些的stacking。
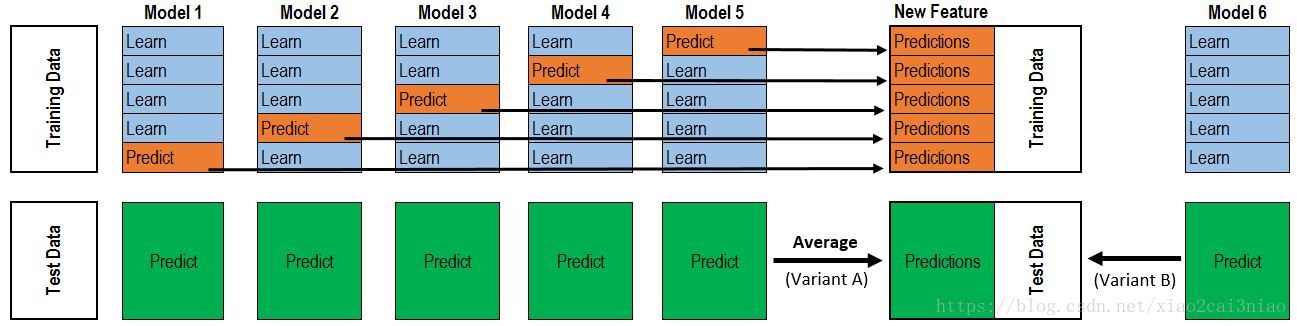
每个模型对训练集做五折交叉验证(可以用sklearn的函数划分出五折的索引),每一折输出验证集的预测结果(softmax概率值)和测试集的预测结果。五个验证集的预测结果可还原为训练集,作为stacking第二层的训练集。测试集的预测结果直接取平均备用。stacking第二层可使用LR、LightGBM、XGBoost等简单分类器,再重复上述五折交叉验证的操作,得到新的训练集,再接一个简单分类器预测最终的结果。
最终第二层选择LightGBM和XGBoost的实验效果较好。
实验
- 使用4.3中提到的预训练模型,调参,微调预测结果。
- 用预训练模型的输出向量作为特征,结合字、词向量,ELMo向量进行实验。
- 使用该任务和问句文本分类(五分类)任务进行多任务学习,模型集成后,效果没有提升。
- 除bert类模型以外,还使用了ESIM模型实验,加入特征后有些许提高,但仍不能超过bert。
最后,我对模型结果进行了后处理,但是由于数据特点,难以找出泛化性强的规则,所以处理之后反而效果有些下降。
写在最后
最后我们队伍的排名为A榜第7,B榜第12,结果不太理想。观察可见,前面队伍直到第二都是在86-87这个区间,只有第一拉开了较大差距,而且这个第一在任务三也是第一,真的强。等到时候评测论文出来,好好学习前面的方法,再总结到blog吧。这个名次也是和自己的努力和能力分不开的,还是要继续努力!


