作者
- Zhen Jia Southwest Jiaotong University, China
- Abdalghani Abujabal MPI for Informatics, Germany
- Rishiraj Saha Roy MPI for Informatics, Germany
- Jannik Strötgen Bosch Center for AI, Germany
- Gerhard Weikum MPI for Informatics, Germany
摘要
基于知识库的问答系统(KBQA)在处理需要分解为子问题的复杂问题时产生了挑战。 本文要解决的是其中重要的一类问题:时间类问题,它需要发现和处理表示时间类关系的线索。 我们提出了TEQUILA系统,这是一种可以在任何KBQA引擎之上运行的时间类QA的方法。 TEQUILA分为四个阶段。首先,它检测问题是否具有询问时间的意图。然后,它分解问题并将其重写为非时间类子问题和时间约束。然后,从底层KBQA引擎检索子问题的答案。最后,TEQUILA根据时间约束来推理计算完整问题的最终答案。与最先进的基准进行比较,证明了了我们方法的可行性。
引言
动机和问题。 KBQA的目标是通过大型知识库(DBpedia、Wikidata、Yago等)或结构化数据来回答问题。KBQA系统的输入问题如下:
Q1: “Which teams did Neymar play for?” /内马尔为哪只队伍效力?
然后把它们翻译成结构化的查询语句,如SPARQL或SQL,并执行来检索答案。这样的做法中,KBQA系统需要去解决输入问题与知识库中的实体、类型和谓词之间词语不匹配的问题:将’Neymar’匹配到唯一确定的实体,将’teams’匹配到知识库中’footballclub’的类型,和将’played for’匹配到知识库中的谓词’memberOf’。目前先进的KBQA方法可以很好地处理像上面例子一样的简单问题,但是处理不好带有多个限制条件、需要把子问题的结果结合起来的复杂问题。例如:
Q2:”After whom did Neymar’s sister choose her last name?” /内马尔的妹妹是谁选的姓氏?
这样的问题就需要内马尔,他的妹妹拉法艾亚和大卫贝克汉姆之间三方的连接。
很重要的一类复杂问题有对时间信息隐式或显式的询问。如下两个例子:
Q3: “Which teams did Neymar play for before joining PSG?”/在加入PSG之前Neymar为哪只队伍效力?
Q4: “Under which coaches did Neymar play in Barcelona?”/在巴塞罗那期间内马尔的教练是谁?
在Q3中没有显式地提到时间,所以一个挑战是检测到它的时间性质。短语’joining PSG’提到了一个事件(内马尔转到这个队伍)。我们可以检测到这个,但是不得不将它消歧成一个标准日期。’before’是一个非常明显的时间性介词,但是像before、after等词也用在非时间性的上下文中;Q2就是一个这样的例子。乍一看Q4,看起来和时间没有什么关系。然而,我们要找的正确答案是在FC巴塞罗那任职期间和内马尔在职期间有交集的那些教练。这种情况检测到时间性质是一个很大的挑战。第二个挑战是如何分解这样的问题并且确保执行后不同的时间段有所交集。
方法和贡献。 本文的核心思想是明智地分解这样的时间类问题,并且重写产生的子问题,这些子问题可以分别被标准的KBQA系统所评价。整个问题的答案由子问题的结果整合推理而来。例如,Q3应该被分解重写成Q3.1: “Which teams did Neymar play for?” /内马尔为哪只队伍效力?和 Q3.2: “When did Neymar join PSG?”/内马尔什么时候加入的PSG。对于问题3.1的结果我们可以从数据库中按时间跨度检索到结果,然后和问题3.2的日期比较得出结果。
我们构建了一个基于规则的框架,包含四个阶段的处理:1)检测时间类问题;2)分解问题并重写子问题;3)检索子问题的候选答案;4)结合并协调之前阶段的结果,推理得到最终答案。对于第三阶段,我们利用现有的KBQA系统(QUINT、AQQU)来得到简单问题的答案。
据我们所知,本文是第一篇针对时间类问题提出完整流水线的论文。新颖的贡献包括,1)一个分解复杂问题的方法;2)基于时间限制的推理,把子问题的答案整合为全局的答案。所有的代码和demo公开。
概念
在NLP中,标记语言TimeML被广泛应用于标注文本文档中的时间信息。文中的时间类问题的定义基于该语言中的概念。
时间表达。 TIMEX3标签给出了四种时间的表达的定义。日期和时间指的是不同粒度的时间点(e.g., ‘May 1, 2010’ and ‘9 pm’, respectively)。它们以完全或未指定的形式出现 (e.g., ‘May 1, 2010’ vs. ‘last year’)。持续时间指的是间隔 (e.g., ‘two years’)。还有周期性时间 (e.g., ‘every Monday’)。
时间信号。 SIGNAL标签标记两个TimeML实体时间的显式时间关系,比如before或者during。我们扩展了TimeML的定义,使其包括当时间被隐式提及的线索,例如‘join PSG’。另外,我们还考虑了序数词,例如first、last等。在问题中当实体可以按时间顺序排序时它们很常见。
时间类问题。 基于以上考虑,我们现在可以定义一个时间类问题是包含时间表达或者时间信号或者问题的答案类型是时间的问题。
时间关系。 Allen引入了13种时间间隔之间的关系进行推理:EQUAL, BEFORE,MEETS, OVERLAPS, DURING, STARTS, FINISHES, 和EQUAL以外的反义词。然而,对于一个时间类问题,并不经常能直接推断出合适的关系。例如之前的Q3的关系应该是BEFORE。但如果我们稍微变化一下,
Q5: “Which team did Neymar play for before joining PSG?”/在加入PSG之前内马尔效力于哪只队伍?(相比Q3 team少了一个s)
这样的话常用的触发词和真实的标签就会有所出入。
方法
给定一个输入问题,TEQULIA工作分四个阶段:1)检测时间类问题;2)分解问题并重写子问题;3)检索子问题的候选答案;4)结合并协调之前阶段的结果,推理得到最终答案。对于第三阶段,我们利用现有的KBQA系统(QUINT、AQQU)来得到简单问题的答案。
检测时间类问题
一个时间类问题被定义为包含以下内容:a)显式或隐式的时间表达(日期、时间、事件);b)时间信号(表示时间关系的词);c)序数词;d)答案类型为时间(例如疑问词为when)。我们使用HeidelTime标记TIMEX3表达。事件用根据freebase构建的词典进行识别。特别地,如果实体类型是‘time.event’,它的表面形式就加入到事件词典里面。SIGNAL词和序数词的检测也是用一个小的词典,并且列出一个时间介词的列表。为了确定问题答案类型是否为事件,我们也列出了一些模板例如when、what date、in what year、which century。
分解与重写问题
TEQUILA把复杂的时间类问题分解成一个或多个非时间类子问题(返回候选答案)和一个或更多的时间类子问题(返回时间限制)。子问题的结果通过取交集结合。时间限制应用于非时间类子问题的结果。为简洁起见,以下解释集中于具有一个非时间类子问题和一个时间类子问题的情况。我们使用一个词法句法规则的集合来分解和重写问题。

基础的规则如下所示:
- 信号词将时间类和非时间类子问题分隔开。
- 每个子问题需要有一个实体和一个关系(动词)使基本的KBQA系统可以处理。
- 如果第二个子问题缺少实体或关系,则向第一个子问题借用。
- KBQA系统对于非语法构造具有鲁棒性,因此排除了在语言上正确的子问题的需求。
回答子问题
子问题被底层的KBQA系统处理成SPARQL查询并在知识库上执行。这样产生了一个子问题结果的集合。非时间类子问题的结果是相同类型的实体(例如足球队),它们是整个问题的候选答案。对多个子问题的答案取交集。而对于时间类子问题,返回的结果是日期这样的时间限制,用来筛选候选答案集合。候选答案需要和时间范围联系起来,为了我们能评价时间限制条件。
检索时间范围。 为了获得时间范围,我们引入了额外的知识库查询,细节取决于底层知识库的详细信息。举例来说,Freebase通常使用CVT结点把三元组和时间范围联系起来;其他的知识库可能使用更多元的元组来给事实附加时空属性。例如,Freebase中的一个谓词marriage就是一个CVT带有配偶(marriage.spouse)和日期(marriage.date)这样的属性。当谓词配偶被用来检索答案时,时间范围通过查找知识库中的marriage.date属性确定。另一方面,为足球俱乐部效力可以和team.player这样的没有时间信息的谓词匹配,在职期间可以由footballPlayer.team.joinedOnDate和footballPlayer.team.leftOnDate谓词的事件属性表示。在这些情况里,TEQUILA系统考虑候选实体的所有时间性谓词,并基于非时间性谓词和潜在相关的时间性谓词之间的相似度筛选。相似度的度量是通过把谓词名称token,然后用word2vec训练得到每个token的向量,对每个谓词中的token向量取平均作为谓词的向量表示,比较两个谓词向量的余弦距离。我们选择匹配度最高的时间性谓词。当需要一个时间段作为限制时,我们会选择一对谓词例如上面的joinedOnDate和leftOnDate。
基于时间段的推理
对于时间类问题,答案可以是时间点、时间段、或者日期的集合(比如某人为一个足球队效力连续的几年的集合)。我们把这些时间段都表示成开始时间点和结束时间点。这些构成了我们测试非时间性候选答案的时间范围所依据的时间性约束,这些时间性约束也被分为begin和end。推理取决于从输入问题中得出的时间运算符(例如,BEFORE,OVERLAP等)。对于出现序数词的问题,我们排序了时间间隔来选择恰当的答案。

实验
实验设置
我们用TempQuestions数据集来评价我们的系统。该数据集包括1271条有标注的时间性问题,包含隐式、显示、和序数词型的时间限制条件,以及该问题的答案。问题和答案来源于Freebase。我们使用了三个最先进的KBQA系统作为基准:AQQU、QUINT和Bao提出的一个系统。前两个是处理简单问题的,第三个可以处理复杂问题包括时间类问题。我们把TEQUILA插入到前两个系统和第三个系统,在ComplexQuestions测试集中341道时间类问题上进行对比。为了评价基准、我们直接把整个问题输入到底层的问答系统中。我们使用PRF评价每个问题,并对整个测试集的结果取平均。
结果和洞察
表格三展示了ComplexQuestions中的341条时间类问题的结果。
TEQUILA使KBQA系统可以回答带时间限制条件的复合问题。 F1值显示加了TEQUILA的系统可以显著超过基准方法。这些系统既没有处理组合语法的能力也不支持专门处理时间类问题。我们的分解重写机制针对组合型问题,限制条件推理对由时间决定答案的问题是关键的。F1分数的提高源于大多数类别中系统地提高了精度。
TEQUILA超过了最先进的基准模型。 Bao等人提出了处理问题中限制条件的通用机制的先进模型。添加了TEQUILA的KBQA模型在时间类问题的回答上超过了Bao等人的方法,表明了为时间信息需求量身定制的方法是值得的。
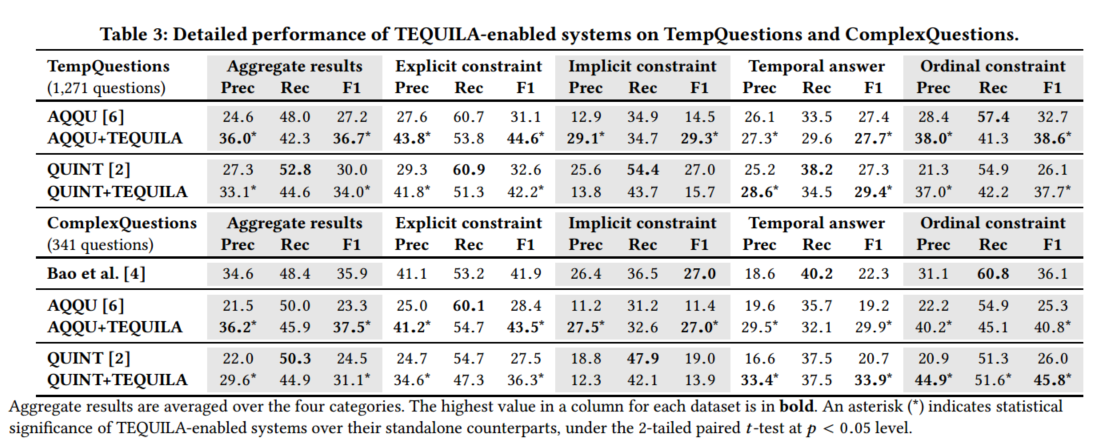
错误分析。 我们分析了TEQUILA的回答错误以指引未来工作的方向:i)分解和重写产生错误。(例如“where did the pilgrims come from before landing in America?”中landing被错误标成了名词,出发了表格1中的case3而不是case1)ii)由于相似度函数的显式,没有发现正确的时间性谓词;iii)推理时使用的时间限制条件或者时间范围含有错误。
相关工作
QA研究在IR和NLP领域有了悠久的传统,一些有名的任务有TREC、CLEF和SemEval。这些任务主要集中于在文本中检索答案。最近的TRECCAR(complex answer retrieval)任务探索多事实片段的答案,但是对信息的需求仍然很单一。在IBM Watson系统中,结构化数据扮演重要角色,但是文本是答案的主要来源。一些基于文本的QA方法应用了问题分解。然而,对答案的重组和推理工作不同于文本来源,不能直接应用于KBQA系统。自然语言句子的组合语义也有人研究。尽管这可以应用于问答,但现有的系统只支持几种特定的复合问题。
KBQA是一个更新的趋势。很多方法关注简单问题,可以被翻译成只有一个未知变量的SPARQL查询。像WebQuestions这样的任务,最好的系统使用模板和语法,利用外部文本信息或者增强训练数据进行端到端学习来解决。这些方法都没有很好的解决复杂问题。Bao等人使用深度学习结合规则来解决复杂问题的多样性。
结论
在QA领域,对复杂问题组合语义的理解是一个开放的挑战。我们关注时间类问题,这是应对重要信息需求的重要步骤。我们的方法在最近的基准测试中表现出了优越的性能,并且在一般复杂问题上的表现均超过了最新水平。我们的工作强调了构建可重复使用的模块的价值,这些模块可改进多个KBQA系统。



