这篇文章是发表于ACL 2020的一篇短文,正文5页,算上附录有14页。
引言
近两年来,文本预训练模型已经在太多的任务上面大放异彩,论文研究层出不穷,并且在工业界也已经慢慢部署开来,解决业界实际难题。像ELMO、BERT有微调和词向量两种使用方式,本文只关心其作为词向量的研究工作,这些词向量带有丰富的上下文信息,可以看做Rich Contextual Embedding。
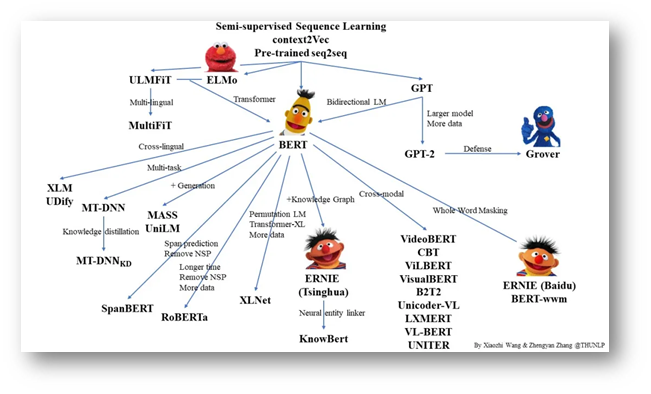
从最开始借鉴Word2vec的工作,到2018年ELMo、BERT、GPT的相继出现,再到各种改进的预训练语言模型的出现,我们可以看到越来越多的计算资源被需要。我们来看看计算资源的消耗:
BERT-base:110M参数,16 TPU, 4天
BERT-Large:340M参数,64 TPU,4天
GPT-2:1542M参数,6.5G,40G文本
GPT-3:1750亿参数,700G(推测),45T文本,使用市场上最快的GPU:Tesla V100单块训练要355年,使用最便宜的GPU训练要花费460万美元,实际花费了1200万美元
并且在GPT-3的74页论文中的第9页还有这样一句话:
> Unfortunately, a bug in the filtering caused us to ignore some overlaps, and due to the cost of training it was not feasible to retrain the model.
由于训练开销,连发现bug都不能轻易修复。
在这种情况之下,这些大模型并不能被大多数人随心使用。应该关心何时使用预训练的上下文相关词向量?什么时候可以采用效率更高的词向量而不会导致性能的显著降低?
实验
词向量
对比了三种词向量:
- •Pretrained contextual embeddings(预训练上下文有关词向量):以BERT和XLNet为代表,对于给定的句子,这些模型将每个标记编码为一个特征向量,该特征向量来自句子中标记上下文的信息。实验中使用768维的 BERT Base
- •Pretrained non-contextual embeddings(预训练上下文无关词向量):以Word2vec、GloVe、fastText为代表,将单词编码为语义信息向量,类似的单词就有相似的向量表示,而不是上下文信息。实验中使用300维公开可获取的GloVe词向量
- •Random embeddings(随机词向量):本文还考虑了将没有预训练的随机词向量作为一个简单有效的 baseline, 词向量随机的方法采用循环随机矩阵(circulant random matrices)。实验中使用800维的随机向量
三种词向量均不微调,微调就不知道是模型的作用还是词向量本身的作用
任务
- 实体识别:数据集:CoNLL-2003;模型:BiLSTM-CRF
- 情感分析:数据集:MR, MPQA, CR, SST, SUBJ, TREC;模型:CNN
- 自然语言理解:数据集:GLUE;模型:BiLSTM
系统效率分析
计算时间
bert推理需要在GPU上花费10ms的时间;GloVe和random花费的时间很少可忽略
存储空间
bert-base参数需要占用440MB空间,如果微调之后还会占用更多空间
GloVe需要保存一个n乘d的矩阵,400k 300维占用480MB空间
随机词向量如果只存储随机种子那么只要O(1)的空间复杂度,如果存储循环随机矩阵那么占用O(n)的时间复杂度,如果n为400k那么占用1.6MB的空间
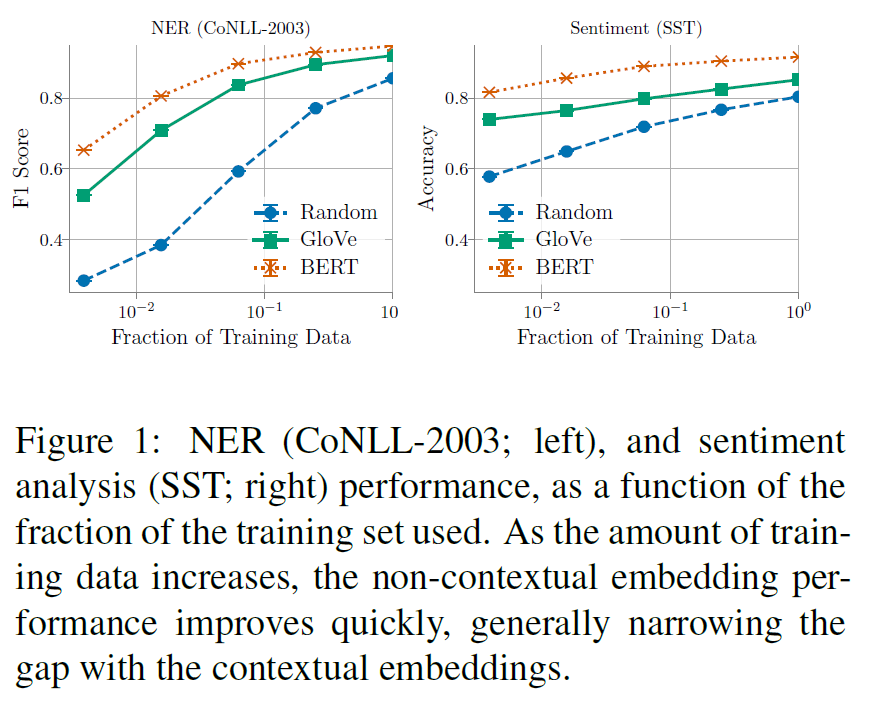
训练数据规模的影响
训练数据最小时,BERT 词向量在两个任务上面都是领先的地位,明显优于 GloVe和 Random词向量,说明 BERT 在小数据上也能有很好的效果。
伴随着训练数据的不断扩增,BERT 词向量也是一直处于领先的位置,但是 GloVe 和 Random 两者的增长趋势很快,最后基本能达到与 BERT 有竞争力的效果。
语言学特性研究
为了更好地理解 BERT 词向量在性能上的巨大提升,该文确定了NLP任务的三个语言特性,看这三个语言特性的影响大小,有助于解释在什么时候会受益。本文针对NER和情感分析任务分别设置了三个指标来衡量每一个样本
Complexity of sentence structure
-
句子中不同单词的相互依赖程度
-
假设内部结构复杂的句子对于上下文无关词向量更难
-
NER:更长的实体更需要对实体名中token之间关系的理解
-
情感分析:依存分析结果中token对的平均距离越长越有挑战
Ambiguity in word usage
-
训练样本中单词的歧义性
-
假设对于训练集中不同场景下的同一单词,上下文无关词向量表现不好
-
NER:训练集中一个token的不同标签数目反映歧义性(e.g., “Washington” appears as a person, location, and organization in CoNLL-2003)
-
情感分析:考虑句子中的单词通常在训练数据中出现在积极或消极句子中来衡量句子的歧义性
Prevalence of unseen words
-
训练样本中未登录词的数量
-
假设上下文有关词向量对于未登录词显著优于上下文无关词向量
-
NER:对于NER输入中的token,我们考虑在训练集中看到token的次数的倒数
-
情感分析:给定一个句子,我们将训练中从未见过的单词在句子中所占比例视为度量


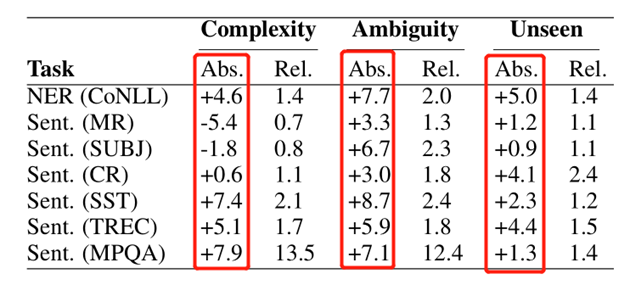
根据上面定义的评价指标,以中位数为分界划分验证集,分别计算bert和baseline词向量的accuracy的差值,然后比较这两部分的结果,若高于中位数的部分大于低于中位数的部分则Abs列为正值。
如下图是 BERT 词向量和 Random 词向量在两种任务上面的实验结果。下图中共有21个Abs值,其中正值有19个,表明 BERT 代表的 Contextual embeddings 在19项上面都表现良好,说明Contextual embeddings 在这三个特性上面有重要的信息增加。
下图是 BERT 词向量和 GloVe 词向量类似上面的实验结果,仔细观察会发现结果与上面有不同,在 Complexity 和 Ambiguity 这两个共14项结果,有11项为正值,表明 Contextual embeddings 在这两个上面还是表现不错的,但是在 Unseen 特性上面,7项里面仅有2个表现的好。说明GloVe和bert在未登录词方面的差距有所减小。
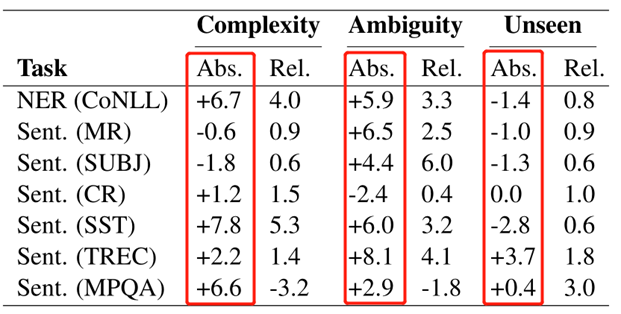
结论:以 BERT 为代表的 Contextual embeddings 在解决一些文本结构复杂度高和单词歧义性方面有显著的效果,但是在未登录词方面 GloVe 代表的Non-Contextual embeddings 有不错的效果。
结论
我们将上下文相关词向量的性能与上下文无关预训练词向量以及甚至更简单的baseline(随机词向量)进行了比较。相对于具有大量标记数据和简单语言的任务的上下文相关词向量,这些上下文无关预训练词向量的效果出奇地好。
尽管学术界和工业界最近做出的令人印象深刻的努力都集中在通过更复杂,因而价格越来越昂贵的嵌入方法来提高最新性能,但这项工作提供了另一种观点,即着眼于在选择或设计embedding方法时进行权衡取舍。 我们希望这项工作能激发人们对更好地理解嵌入方法之间的差异以及设计更简单,更有效的模型的未来研究。

