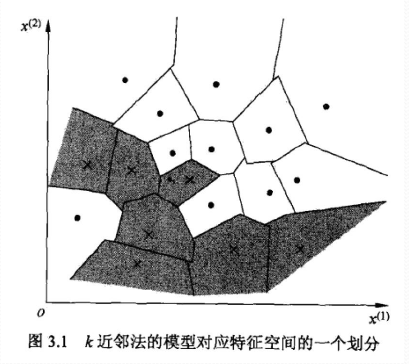
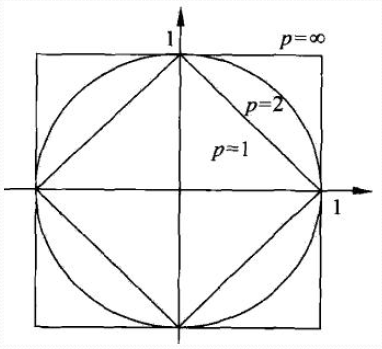
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
import numpy as np
class Node:
def __init__(self, data, lchild = None, rchild = None):
self.data = data
self.lchild = lchild
self.rchild = rchild
class KdTree:
def __init__(self):
self.kdTree = None
def create(self, dataSet, depth):
if (len(dataSet) > 0):
m, n = np.shape(dataSet)
midIndex = int(m / 2)
axis = depth % n
sortedDataSet = sorted(dataSet,key = lambda x:x[axis])
node = Node(sortedDataSet[midIndex])
leftDataSet = sortedDataSet[: midIndex]
rightDataSet = sortedDataSet[midIndex+1 :]
node.lchild = self.create(leftDataSet, depth+1)
node.rchild = self.create(rightDataSet, depth+1)
return node
else:
return None
def preOrder(self, node):
if node != None:
print("tttt->%s" % node.data)
self.preOrder(node.lchild)
self.preOrder(node.rchild)
def search(self, tree, x):
self.nearestPoint = None
self.nearestValue = 0
def travel(node, depth = 0):
if node != None:
n = len(x)
axis = depth % n
if x[axis] < node.data[axis]:
travel(node.lchild, depth+1)
else:
travel(node.rchild, depth+1)
distNodeAndX = self.dist(x, node.data)
if (self.nearestPoint == None):
self.nearestPoint = node.data
self.nearestValue = distNodeAndX
elif (self.nearestValue > distNodeAndX):
self.nearestPoint = node.data
self.nearestValue = distNodeAndX
print(node.data, depth, self.nearestValue, node.data[axis], x[axis])
if (abs(x[axis] - node.data[axis]) <= self.nearestValue):
if x[axis] < node.data[axis]:
travel(node.rchild, depth+1)
else:
travel(node.lchild, depth + 1)
travel(tree)
return self.nearestPoint
def dist(self, x1, x2):
return ((np.array(x1) - np.array(x2)) ** 2).sum() ** 0.5
dataSet = [[2, 3],
[5, 4],
[9, 6],
[4, 7],
[8, 1],
[7, 2]]
x = [5, 3]
kdtree = KdTree()
tree = kdtree.create(dataSet, 0)
kdtree.preOrder(tree)
print(kdtree.search(tree, x))
|