最近做项目用到了哈工大的LTP,假期期间一直在自己笔记本电脑上开发,用的是最新的LTP4。因为自己的电脑环境是CUDA 10,并且安装的是PyTorch 1.6,所以没遇到什么问题。在迁移到服务器环境的时候,发现LTP4要求PyTorch版本>=1.2.0,于是不得不降级LTP版本。记录一下在Ubuntu服务器安装LTP 3.4.0,以及python调用的过程。
LTP 4
LTP 4.0的安装就很方便,执行如下语句即可安装
快速使用
1
2
3
4
5
6
7
8
9
| from ltp import LTP
ltp = LTP()
segment, hidden = ltp.seg(["他叫汤姆去拿外衣。"])
pos = ltp.pos(hidden)
ner = ltp.ner(hidden)
srl = ltp.srl(hidden)
dep = ltp.dep(hidden)
sdp = ltp.sdp(hidden)
|
LTP 3.4.0
pyltp安装
LTP 3.4.0对应的Python包为pyltp,在服务器上直接pip install pyltp之后会在某一步停住,所以采用官网文档提供的从源码安装。
1
2
3
4
5
| git clone https://github.com/HIT-SCIR/pyltp
cd pyltp
git submodule init
git submodule update
python setup.py install
|
执行上述步骤之后,可以看到已经安装好了pyltp 0.4.0版本。
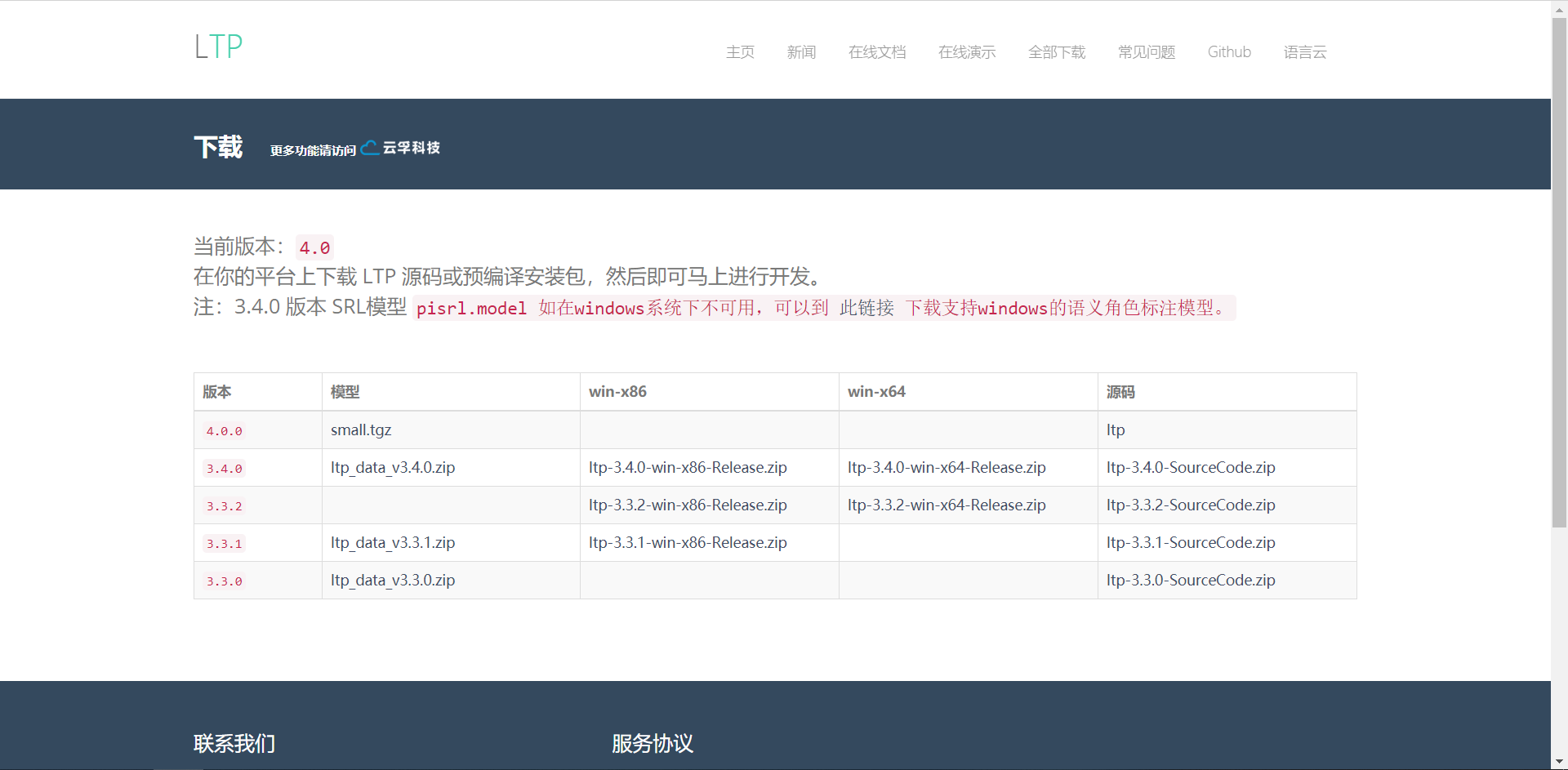
模型下载
点击此处可以下载对应的版本,这里下载的是ltp_data_v3.4.0.zip,在服务器上建个文件夹解压到里面即可。
Python调用
由于网上大部分的使用说明都是对应pyltp 0.2.x版本的,pyltp 0.4.0版本的调用各种分词器的函数读取模型是有些微小的改变。
分句器
1
2
3
| from pyltp import SentenceSplitter
sents = SentenceSplitter.split('元芳你怎么看?我就趴窗口上看呗!')
print('分句结果',sents)
|
LTP模型路径
1
| LTP_DATA_DIR = "你的LTP模型解压后的文件夹路径,例如 /home/DUTIR/lishuaichi/ltp_model/"
|
分词器
1
2
3
4
5
6
7
8
9
10
| cws_model_path=os.path.join(LTP_DATA_DIR,'cws.model')
segmentor=Segmentor(cws_model_path)
words=segmentor.segment('熊高雄你吃饭了吗')
print('分词结果',words)
segmentor.release()
|
加载自定义词典
1
2
3
4
5
6
7
| segmentor=Segmentor(cws_model_path,'lexicon')
'''lexicon文件内容,用tab隔开
熊高雄你 n
'''
words=segmentor.segment('熊高雄你吃饭了吗')
print(words)
segmentor.release()
|
词性标注
1
2
3
4
5
6
| pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model')
postagger = Postagger(pos_model_path,'lexicon')
words = ['元芳', '你', '怎么', '看']
postags = postagger.postag(words)
print('\t'.join(postags))
postagger.release()
|
依存句法分析
1
2
3
4
5
6
7
8
| par_model_path = os.path.join(LTP_DATA_DIR, 'parser.model')
parser = Parser(par_model_path)
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
arcs = parser.parse(words, postags)
print([arc for arc in arcs])
parser.release()
|
语义角色标注
1
2
3
4
5
6
7
| srl_model_path = os.path.join(LTP_DATA_DIR, 'pisrl.model')
labeller = SementicRoleLabeller(srl_model_path)
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
roles = labeller.label(words, postags, arcs)
labeller.release()
|
实体识别
1
2
3
4
5
6
7
8
9
| ner_model_path = os.path.join(LTP_DATA_DIR, 'ner.model')
recognizer = NamedEntityRecognizer(ner_model_path)
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
netags = recognizer.recognize(words, postags)
print('\t'.join(netags))
recognizer.release()
|

