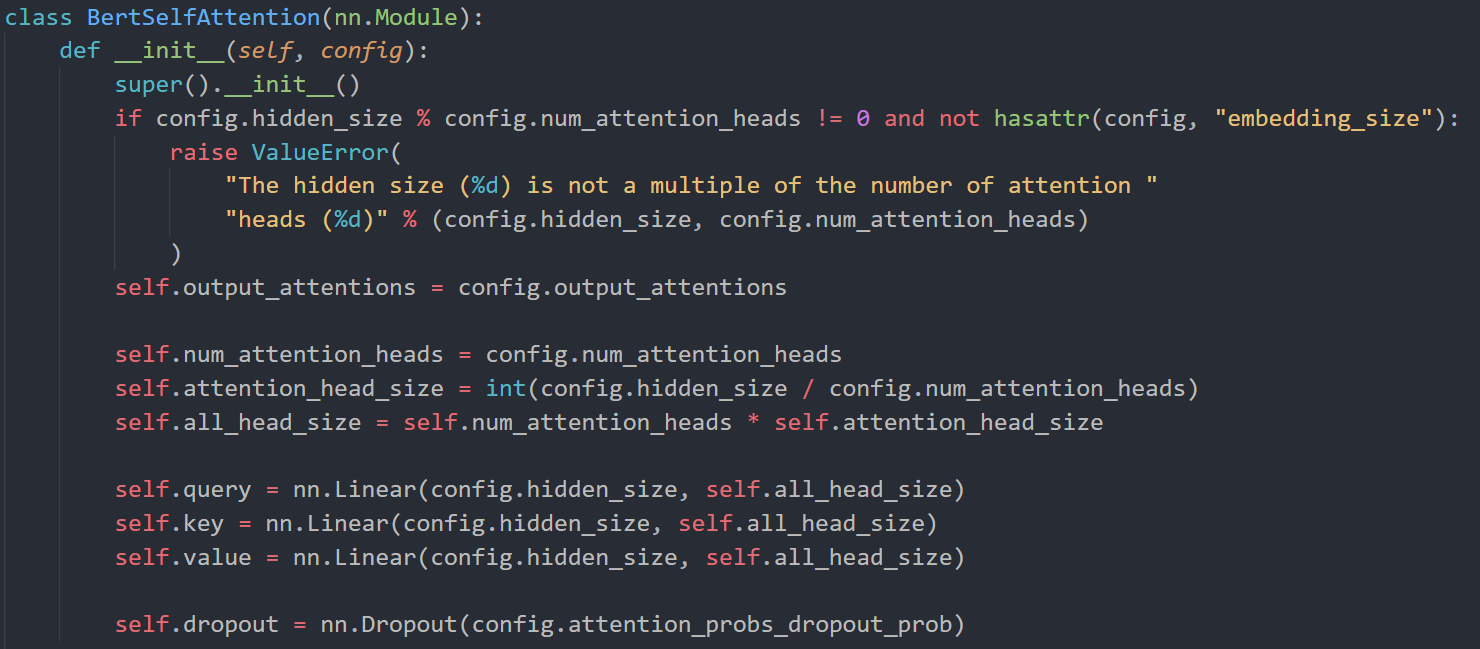
BERT结构
BERT是Bidirectional Encoder Representations from Transformers的缩写,它使用的是Transformer结构的Encoder部分。
BERT base 12层 768隐藏单元 12个head 共110M
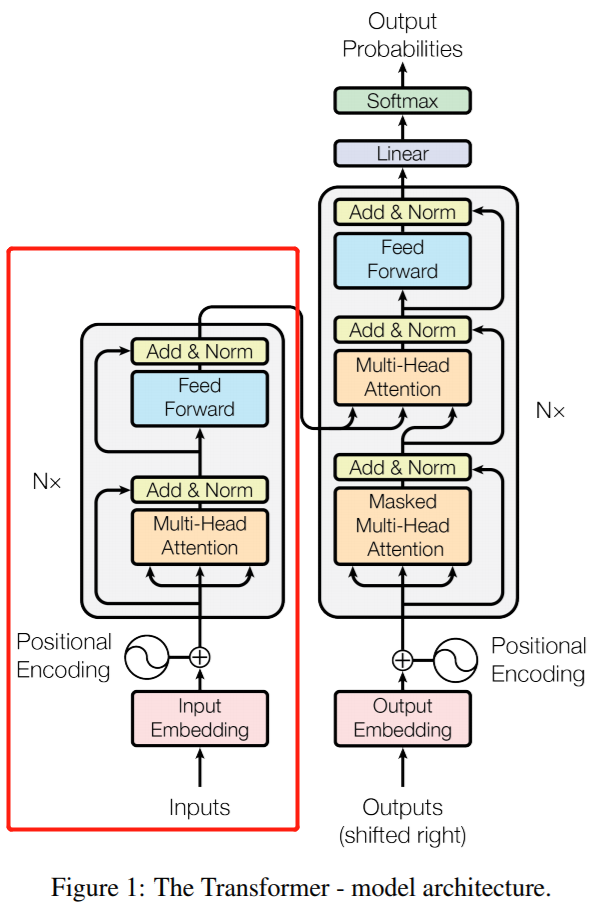
输入部分
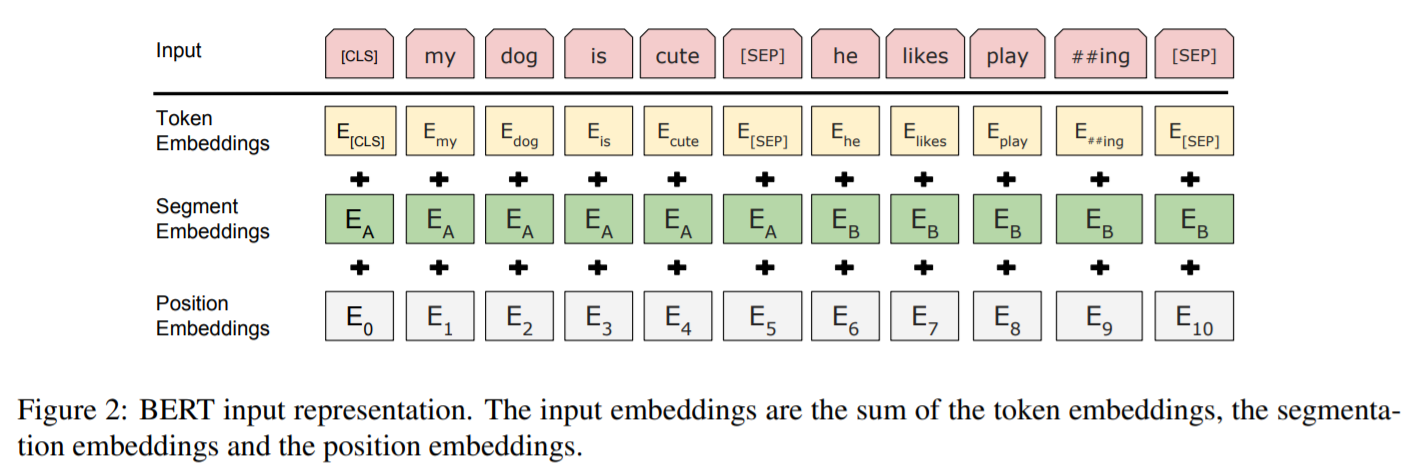
BERT的输入由三部分组成:Token Embeddings、Segment Embeddings和Position Embeddings。根据代码中的定义可以看到它们的尺寸分别是:vocab_size * hidden_size、type_vocab_size * hidden_size和max_position_embeddings * hidden_size。
vocab_size=30522, hidden_size=768, max_position_embeddings=512, token_type_embeddings=2(1和0区别输入的两个句子)
所以输入部分参数量就是(30522+512+2)*768 = 23835648
然后上面的三种向量相加,经过layer normalization和dropout得到Embedding表示。
layer normalization的公式是
其中是可训练的参数,每个维度都包含这两个
所以是768维*2 = 1536
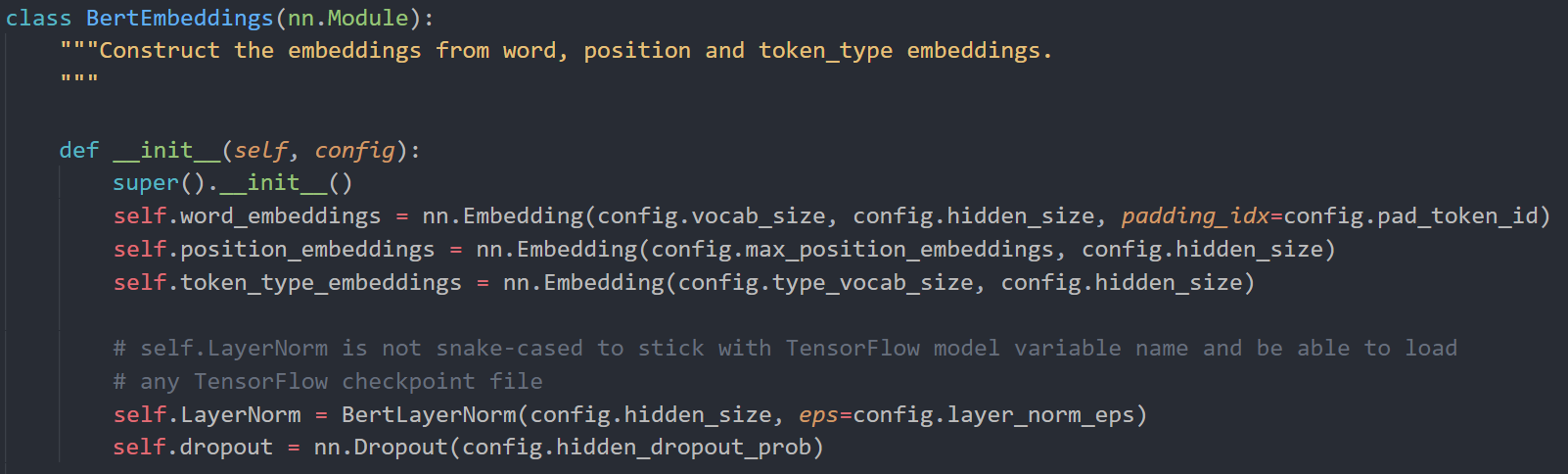
多头attention部分
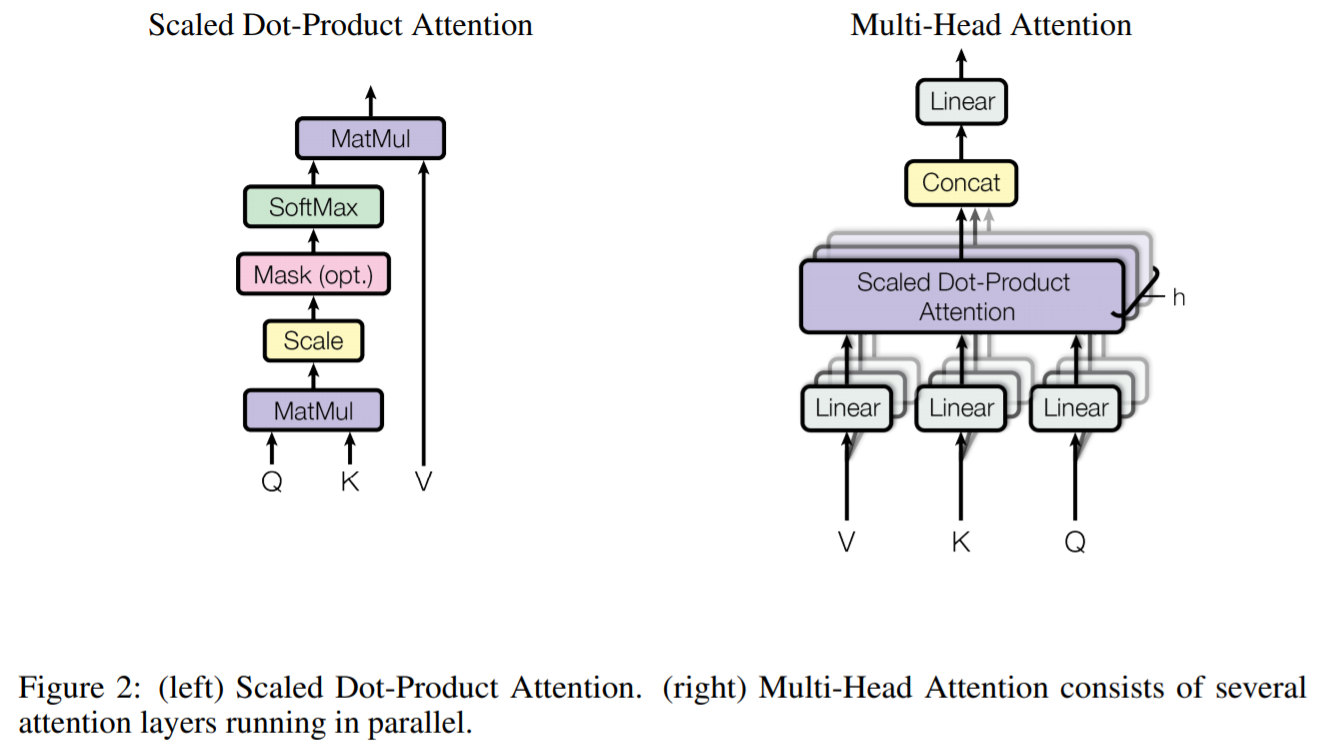
BERT中多头attention的头的数量是12,每个头的attention结果拼接在一起之后的长度就是768维,所以每一个头输出的维度是768÷12 = 64
每一次做attention都要对隐层向量做Q、K、V的变换,那么Q、K、V的shape都是hidden_size * one_head_size,再加上bias。于是,所有头的合计的参数是12*(768*64*3+64*3) =1,771,776
(这一步感觉pytorch的源码中没有体现)所有头拼接之后又做了线性变换,变换矩阵的shape是768*768,bias是768
所以这部分参数合计为12*(768*64*3)+768*768+768 = 2,362,368
前馈网络(Feed Forward Network)
的大小为768*3072,的大小为3072*768。
第一层:768*3072(原文中4H长度) + 3072=2360064
第二层:3072*768+768=2362368
总结
Embedding部分
(30522+512+2)*768+768*2
self attention部分
768*12*64*3+12*64*3是自注意层12个多头Q,K,V对应的参数量;
64*12*768+768是将自注意层12个多头输出进行拼接后接全连接层输出对应的参数量;
768+768是自注意层后接归一层的参数beta和gamma;
FFN部分
768*3072+3072是前馈神经网络进行调制生成全连接层输出对应的参数;
3072*768+768则是前馈神经网络进行解调生成全连接层输出对应的参数;
768+768是前馈神经网络层后接归一层的参数beta和gamma。
合计
合计(30522+512+2)*768+768*2+12*(768*12*64*3+12*64*3+64*12*768+768*2+768*3072+3072+3072*768+768+768*2) = 108,882,432约等于官网的110M参数,这里没有算下游两个任务的参数。
# 23,837,184+7,087,104*12= 23,837,184+85,045,248


