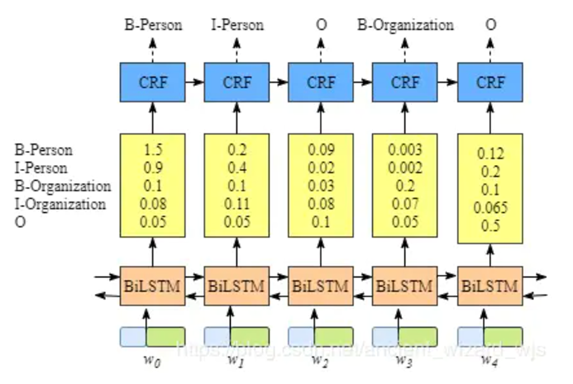
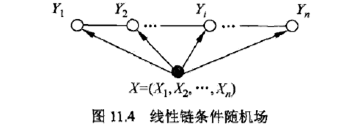
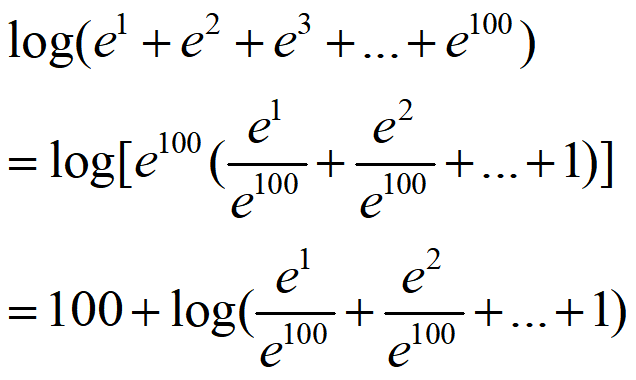序列标注任务一个效果不错的模型就是BiLSTM-CRF模型,将输入句子序列通过embedding层得到词向量表示,然后输入到BiLSTM编码成隐层向量,该隐层向量作为CRF层的输入(即发射矩阵)后,输出每个词对应的标签序列。序列标注任务中,常用的标签体系有BMES、BIO、BIOES等。
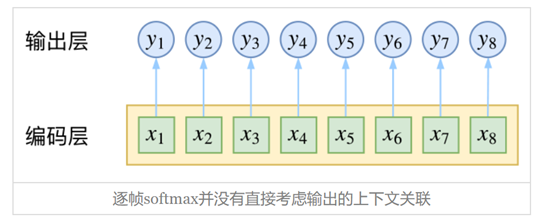
如果不适用CRF层,那么就相当于对每个标签位置的隐层向量使用softmax分类,取归一化概率最大的标签作为最终输出,相当于n个k分类任务。(n是序列长度,k是标签数量)
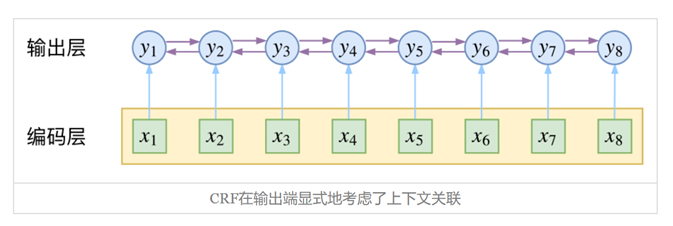
而CRF层考虑输出标签之间的关联,例如定义上是I标签只能出现在B标签之后,通过训练让CRF层能过滤掉这种不符合定义的组合。
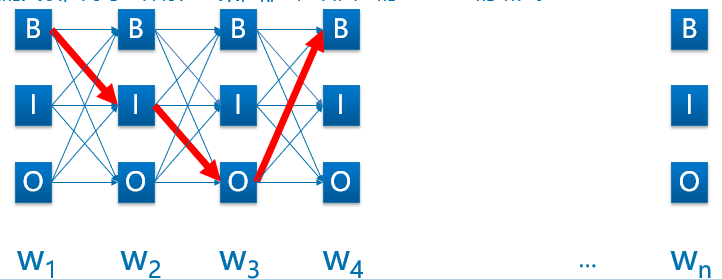
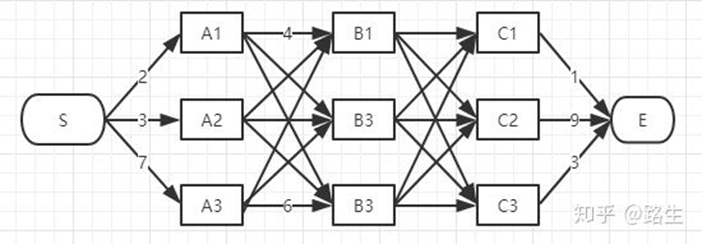
CRF以路径为单位,考虑的是路径整体的概率,如下图所示,每一种标注结果都对应着一条路径。序列长度为n,标签种类为k,那么可能的路径组合就有k n k^n k n k n k^n k n
在训练过程中,我们希望让训练集中标注的正确路径的概率在所有路径中的概率是最大的,先来看看如何表示路径的概率。
我们要计算的是条件概率:
P ( y 1 , … , y n ∣ x 1 , … , x n ) = P ( y 1 , … , y n ∣ x ) , x = ( x 1 , … , x n ) P(y_1,\dots,y_n|x_1,\dots,x_n)=P(y_1,\dots,y_n|x), x=(x1,\dots,x_n)
P ( y 1 , … , y n ∣ x 1 , … , x n ) = P ( y 1 , … , y n ∣ x ) , x = ( x 1 , … , x n )
假设该分布是指数族分布,存在函数f ( y 1 , … , y n ; x ) f(y_1,\dots,y_n;x) f ( y 1 , … , y n ; x )
P ( y 1 , … , y n ∣ x ) = 1 Z ( x ) e x p ( f ( y 1 , … , y n ; x ) ) P(y_1,\dots,y_n|x) = \frac{1}{Z(x)}exp(f(y_1,\dots,y_n;x))
P ( y 1 , … , y n ∣ x ) = Z ( x ) 1 e x p ( f ( y 1 , … , y n ; x ) )
其中,分母1 Z ( x ) \frac{1}{Z(x)} Z ( x ) 1 x x x f f f
一般我们序列标注用的是线性链条件随机场,相邻的输出标签之间满足马尔可夫性:P ( Y i ∣ X , Y 1 , Y 2 , … , Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) P(Y_i|X,Y_1,Y_2,\dots,Y_n) = P(Y_i|X,Y_{i-1},Y_{i+1}) P ( Y i ∣ X , Y 1 , Y 2 , … , Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 )
由于上面是指数族分布,所以打分函数f可以简化成概率相加的形式:
f ( y 1 , … , y n ; x ) = h ( y 1 ; x ) + g ( y 1 , y 2 ; x ) + h ( y 2 ; x ) + g ( y 2 , y 3 ; x ) + h ( y 3 ; x ) + ⋯ + g ( y n − 1 , y n ; x ) + h ( y n ; x ) f(y_1,\dots,y_n;x)=h(y_1;x)+g(y_1,y_2;x)+h(y_2;x)+g(y_2,y_3;x)+h(y_3;x)+\dots+g(y_{n-1},y_n;x)+h(y_n;x)
f ( y 1 , … , y n ; x ) = h ( y 1 ; x ) + g ( y 1 , y 2 ; x ) + h ( y 2 ; x ) + g ( y 2 , y 3 ; x ) + h ( y 3 ; x ) + ⋯ + g ( y n − 1 , y n ; x ) + h ( y n ; x )
然后假设训练过程可以让函数$ g$仅依赖于相邻标签,而不依赖于输入序列(个人理解),上式就可以简化为:
f ( y 1 , … , y n ; x ) = h ( y 1 ; x ) + g ( y 1 , y 2 ) + h ( y 2 ; x ) + g ( y 2 , y 3 ) + h ( y 3 ; x ) + ⋯ + g ( y n − 1 , y n ) + h ( y n ; x ) f(y_1,\dots,y_n;x)=h(y_1;x)+g(y_1,y_2)+h(y_2;x)+g(y_2,y_3)+h(y_3;x)+\dots+g(y_{n-1},y_n)+h(y_n;x)
f ( y 1 , … , y n ; x ) = h ( y 1 ; x ) + g ( y 1 , y 2 ) + h ( y 2 ; x ) + g ( y 2 , y 3 ) + h ( y 3 ; x ) + ⋯ + g ( y n − 1 , y n ) + h ( y n ; x )
继续,上面的打分函数$ f$,就可以理解成如下形式:
s ( X , y ) = ∑ i = 0 n A y i , y i + 1 + ∑ i = 1 n P i , y i s(X,y) = \sum_{i=0}^nA_{y_i,y_{i+1}}+\sum_{i=1}^nP_{i,y_i}
s ( X , y ) = i = 0 ∑ n A y i , y i + 1 + i = 1 ∑ n P i , y i
其中,A A A ( k + 2 ) × ( k + 2 ) (k+2)×(k+2) ( k + 2 ) × ( k + 2 ) A y i , y i + 1 A_{y_i,y_{i+1}} A y i , y i + 1 y i y_i y i y i + 1 y_{i+1} y i + 1
P P P n × ( k + 2 ) n×(k+2) n × ( k + 2 ) P i , y i P_{i,y_i} P i , y i i i i i i i y i y_i y i
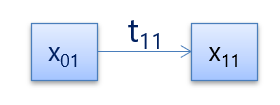
于是,下图这样简单的路径打分即为:
S a _ p o s s i b l e _ p a t h = e m i s s i o n _ s c o r e + t r a n s i t i o n _ s c o r e = x 01 + x 11 + t 11 S_{a\_possible\_path} = emission\_score+transition\_score = x_{01}+x_{11}+t_{11}
S a _ p o s s i b l e _ p a t h = e m i s s i o n _ s c o r e + t r a n s i t i o n _ s c o r e = x 0 1 + x 1 1 + t 1 1
现在有了上面的打分函数,带入之前的指数族分布函数,我们要表示路径的概率就变成了:
p ( y ∣ X ) = e s ( X , y ) ∑ y ~ ∈ Y X e s ( X , y ~ ) p(y|X) = \frac{e^{s(X,y)}}{\sum_{\tilde{y}\in Y_X}e^{s(X,\tilde{y})}}
p ( y ∣ X ) = ∑ y ~ ∈ Y X e s ( X , y ~ ) e s ( X , y )
其中,分子是正确路径的得分,分母是所有可能路径的总得分
训练过程中,我们要最大化正确路径的似然概率:
l o g ( p ( y ∣ X ) ) = l o g ( e s ( X , y ) ∑ y ~ ∈ Y X e s ( X , y ~ ) ) = s ( X , y ) − l o g ( ∑ y ~ ∈ Y X e s ( X , y ~ ) ) log(p(y|X)) = log(\frac{e^{s(X,y)}}{\sum_{\tilde{y}\in Y_X}e^{s(X,\tilde{y})}})= s(X,y)-log(\sum_{\tilde{y}\in Y_X}e^{s(X,\tilde{y})})
l o g ( p ( y ∣ X ) ) = l o g ( ∑ y ~ ∈ Y X e s ( X , y ~ ) e s ( X , y ) ) = s ( X , y ) − l o g ( y ~ ∈ Y X ∑ e s ( X , y ~ ) )
为了用梯度下降学习参数,我们在上式前面加符号,得到损失函数,就变成了两项相减的形式:
L o s s = l o g ( ∑ y ~ ∈ Y X e s ( X , y ~ ) ) − s ( X , y ) Loss =log(\sum_{\tilde{y}\in Y_X}e^{s(X,\tilde{y})})-s(X,y)
L o s s = l o g ( y ~ ∈ Y X ∑ e s ( X , y ~ ) ) − s ( X , y )
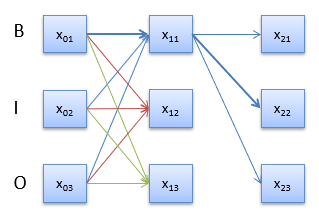
我们现在有了损失函数,在训练过程中便可以计算损失了。第二项式正确路径的得分,这个根据当前的转移矩阵和发射矩阵很容易计算。而第一项所有可能路径的总得分就比较难计算了。之前提到,可能的路径共有k n k^n k n x 11 x_{11} x 1 1 x 01 → x 11 , x 02 → x 11 , x 03 → x 11 x_{01}\rightarrow x_{11},x_{02}\rightarrow x_{11},x_{03}\rightarrow x_{11} x 0 1 → x 1 1 , x 0 2 → x 1 1 , x 0 3 → x 1 1 x 11 x_{11} x 1 1 x 12 , x 13 x_{12},x_{13} x 1 2 , x 1 3 k 2 × n k^2×n k 2 × n
当n=2时,前向算法的过程如上图所示。首先初始化0时刻的forward向量。然后将f o r w a r d forward f o r w a r d f o r w a r d forward f o r w a r d e m i s s i o n emission e m i s s i o n t r a n s i t i o n transition t r a n s i t i o n f o r w a r d forward f o r w a r d f o r w a r d forward f o r w a r d t o t a l total t o t a l f o r w a r d forward f o r w a r d
f o r w a r d 2 [ 0 ] = l o g ( e l o g ( e x 01 + x 11 + t 11 + e x 02 + x 11 + t 21 + e x 03 + x 11 + t 31 ) + x 21 + t 11 + e l o g ( e x 01 + x 12 + t 12 + e x 02 + x 12 + t 22 + e x 03 + x 12 + t 32 ) + x 21 + t 21 + e l o g ( e x 01 + x 13 + t 13 + e x 02 + x 13 + t 23 + e x 03 + x 13 + t 33 ) + x 21 + t 31 ) forward_2[0]=log(e^{log(e^{x_{01}+x_{11}+t_{11}}+e^{x_{02}+x_{11}+t_{21}}+e^{x_{03}+x_{11}+t_{31}})+x_{21}+t_{11}}+
e^{log(e^{x_{01}+x_{12}+t_{12}}+e^{x_{02}+x_{12}+t_{22}}+e^{x_{03}+x_{12}+t_{32}})+x_{21}+t_{21}}+
e^{log(e^{x_{01}+x_{13}+t_{13}}+e^{x_{02}+x_{13}+t_{23}}+e^{x_{03}+x_{13}+t_{33}})+x_{21}+t_{31}})
f o r w a r d 2 [ 0 ] = l o g ( e l o g ( e x 0 1 + x 1 1 + t 1 1 + e x 0 2 + x 1 1 + t 2 1 + e x 0 3 + x 1 1 + t 3 1 ) + x 2 1 + t 1 1 + e l o g ( e x 0 1 + x 1 2 + t 1 2 + e x 0 2 + x 1 2 + t 2 2 + e x 0 3 + x 1 2 + t 3 2 ) + x 2 1 + t 2 1 + e l o g ( e x 0 1 + x 1 3 + t 1 3 + e x 0 2 + x 1 3 + t 2 3 + e x 0 3 + x 1 3 + t 3 3 ) + x 2 1 + t 3 1 )
实际上,这样计算满足的公式就是:
l o g ( ∑ e l o g ( ∑ e x ) + y ) = l o g ( ∑ ∑ e x + y ) log(\sum e^{log(\sum e^x)+y}) = log(\sum\sum e^{x+y})
l o g ( ∑ e l o g ( ∑ e x ) + y ) = l o g ( ∑ ∑ e x + y )
可以手动推导一下,很简单。
下面是pytorch官方教程里面的代码实现:
首先代码中定义了取指数和对数的函数log_sum_exp:
1 2 3 4 5 6 7 8 9 def log_sum_exp (vec ): max_score = vec[0 , argmax(vec)] max_score_broadcast = max_score.view(1 , -1 ).expand(1 , vec.size()[1 ]) return max_score + \ torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
下面是前向算法的代码实现,定义了函数_forward_alg:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def _forward_alg (self, feats ): init_alphas = torch.full((1 , self.tagset_size), -10000. ) init_alphas[0 ][self.tag_to_ix[START_TAG]] = 0. forward_var = init_alphas for feat in feats: alphas_t = [] for next_tag in range(self.tagset_size): emit_score = feat[next_tag].view( 1 , -1 ).expand(1 , self.tagset_size) trans_score = self.transitions[next_tag].view(1 , -1 ) next_tag_var = forward_var + trans_score + emit_score alphas_t.append(log_sum_exp(next_tag_var).view(1 )) forward_var = torch.cat(alphas_t).view(1 , -1 ) terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]] alpha = log_sum_exp(terminal_var) return alpha
通过训练过程我们可以确定最优的发射矩阵和转移矩阵,那么在预测过程,就是要根据已有的发射矩阵和转移矩阵,计算得分最高的路径是哪一条,而这条路径也就是当前输入序列的标注序列结果。
求解我们使用维特比算法,维特比算法解决的是篱笆型的图的最短路径问题,图的节点按列组织,每列的节点数量可以不一样,每一列的节点只能和相邻列的节点相连,不能跨列相连,节点之间有着不同的距离。使用动态规划的思想,将时间复杂度从O ( K N ) O(K^N) O ( K N ) O ( K 2 × N ) O(K^2×N) O ( K 2 × N )
这里引用知乎回答中的图示。
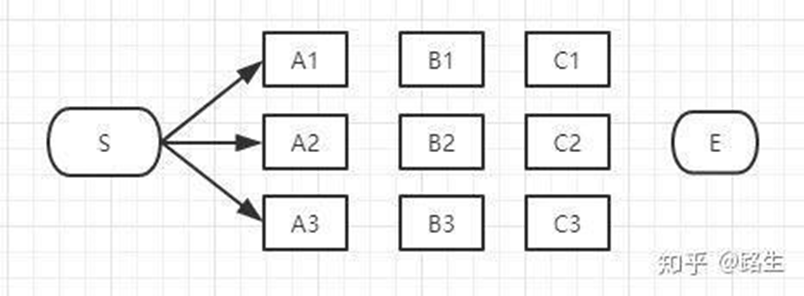
初始时刻,有三条路径:S → A 1 , S → A 2 , S → A 3 S\rightarrow A_1,S\rightarrow A_2,S\rightarrow A_3 S → A 1 , S → A 2 , S → A 3
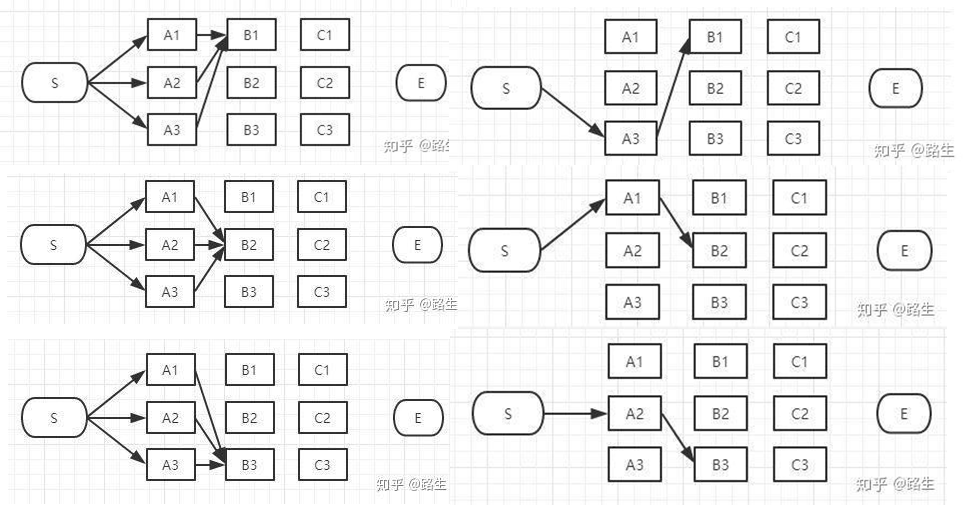
下一时刻的每一个标签都可以由上一时刻的三条路径到达,计算得分,保留得分最高的一条路径。t1时刻结束,我们依然保有三条路径。每个时刻我们都记录到当前时刻每一个标签状态的最大得分,以及上一时刻是从哪一个标签状态转移过来的。
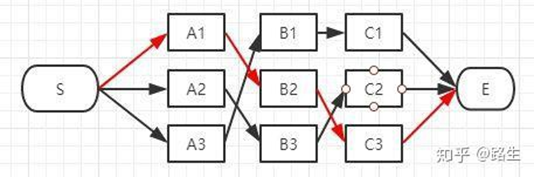
循环上述步骤,最终我们得到了通向终止状态的三条路径,我们要比较这三条路径的得分,选择最大得分的路径作为最终结果。再根据记录的路径列表,反向查找出路径上的状态结点都是哪些,算法结束。
下面是pytorch官方教程中的代码实现,定义了函数_viterbi_decode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 def _viterbi_decode (self, feats ): backpointers = [] init_vvars = torch.full((1 , self.tagset_size), -10000. ) init_vvars[0 ][self.tag_to_ix[START_TAG]] = 0 forward_var = init_vvars for feat in feats: bptrs_t = [] viterbivars_t = [] for next_tag in range(self.tagset_size): next_tag_var = forward_var + self.transitions[next_tag] best_tag_id = argmax(next_tag_var) bptrs_t.append(best_tag_id) viterbivars_t.append(next_tag_var[0 ][best_tag_id].view(1 )) forward_var = (torch.cat(viterbivars_t) + feat).view(1 , -1 ) backpointers.append(bptrs_t) terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]] best_tag_id = argmax(terminal_var) path_score = terminal_var[0 ][best_tag_id] best_path = [best_tag_id] for bptrs_t in reversed(backpointers): best_tag_id = bptrs_t[best_tag_id] best_path.append(best_tag_id) start = best_path.pop() assert start == self.tag_to_ix[START_TAG] best_path.reverse() return path_score, best_path
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 import torchimport torch.autograd as autogradimport torch.nn as nnimport torch.optim as optimtorch.manual_seed(1 ) def argmax (vec ): _, idx = torch.max(vec, 1 ) return idx.item() def prepare_sequence (seq, to_ix ): idxs = [to_ix[w] for w in seq] return torch.tensor(idxs, dtype=torch.long) def log_sum_exp (vec ): max_score = vec[0 , argmax(vec)] max_score_broadcast = max_score.view(1 , -1 ).expand(1 , vec.size()[1 ]) return max_score + \ torch.log(torch.sum(torch.exp(vec - max_score_broadcast))) class BiLSTM_CRF (nn.Module ): def __init__ (self, vocab_size, tag_to_ix, embedding_dim, hidden_dim ): super(BiLSTM_CRF, self).__init__() self.embedding_dim = embedding_dim self.hidden_dim = hidden_dim self.vocab_size = vocab_size self.tag_to_ix = tag_to_ix self.tagset_size = len(tag_to_ix) self.word_embeds = nn.Embedding(vocab_size, embedding_dim) self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2 , num_layers=1 , bidirectional=True ) self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size) self.transitions = nn.Parameter( torch.randn(self.tagset_size, self.tagset_size)) self.transitions.data[tag_to_ix[START_TAG], :] = -10000 self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000 self.hidden = self.init_hidden() def init_hidden (self ): return (torch.randn(2 , 1 , self.hidden_dim // 2 ), torch.randn(2 , 1 , self.hidden_dim // 2 )) def _forward_alg (self, feats ): init_alphas = torch.full((1 , self.tagset_size), -10000. ) init_alphas[0 ][self.tag_to_ix[START_TAG]] = 0. forward_var = init_alphas for feat in feats: alphas_t = [] for next_tag in range(self.tagset_size): emit_score = feat[next_tag].view( 1 , -1 ).expand(1 , self.tagset_size) trans_score = self.transitions[next_tag].view(1 , -1 ) next_tag_var = forward_var + trans_score + emit_score alphas_t.append(log_sum_exp(next_tag_var).view(1 )) forward_var = torch.cat(alphas_t).view(1 , -1 ) terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]] alpha = log_sum_exp(terminal_var) return alpha def _get_lstm_features (self, sentence ): self.hidden = self.init_hidden() embeds = self.word_embeds(sentence).view(len(sentence), 1 , -1 ) lstm_out, self.hidden = self.lstm(embeds, self.hidden) lstm_out = lstm_out.view(len(sentence), self.hidden_dim) lstm_feats = self.hidden2tag(lstm_out) return lstm_feats def _score_sentence (self, feats, tags ): score = torch.zeros(1 ) tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long), tags]) for i, feat in enumerate(feats): score = score + \ self.transitions[tags[i + 1 ], tags[i]] + feat[tags[i + 1 ]] score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1 ]] return score def _viterbi_decode (self, feats ): backpointers = [] init_vvars = torch.full((1 , self.tagset_size), -10000. ) init_vvars[0 ][self.tag_to_ix[START_TAG]] = 0 forward_var = init_vvars for feat in feats: bptrs_t = [] viterbivars_t = [] for next_tag in range(self.tagset_size): next_tag_var = forward_var + self.transitions[next_tag] best_tag_id = argmax(next_tag_var) bptrs_t.append(best_tag_id) viterbivars_t.append(next_tag_var[0 ][best_tag_id].view(1 )) forward_var = (torch.cat(viterbivars_t) + feat).view(1 , -1 ) backpointers.append(bptrs_t) terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]] best_tag_id = argmax(terminal_var) path_score = terminal_var[0 ][best_tag_id] best_path = [best_tag_id] for bptrs_t in reversed(backpointers): best_tag_id = bptrs_t[best_tag_id] best_path.append(best_tag_id) start = best_path.pop() assert start == self.tag_to_ix[START_TAG] best_path.reverse() return path_score, best_path def neg_log_likelihood (self, sentence, tags ): feats = self._get_lstm_features(sentence) forward_score = self._forward_alg(feats) gold_score = self._score_sentence(feats, tags) return forward_score - gold_score def forward (self, sentence ): lstm_feats = self._get_lstm_features(sentence) score, tag_seq = self._viterbi_decode(lstm_feats) return score, tag_seq START_TAG = "<START>" STOP_TAG = "<STOP>" EMBEDDING_DIM = 5 HIDDEN_DIM = 4 training_data = [( "the wall street journal reported today that apple corporation made money" .split(), "B I I I O O O B I O O" .split() ), ( "georgia tech is a university in georgia" .split(), "B I O O O O B" .split() )] word_to_ix = {} for sentence, tags in training_data: for word in sentence: if word not in word_to_ix: word_to_ix[word] = len(word_to_ix) tag_to_ix = {"B" : 0 , "I" : 1 , "O" : 2 , START_TAG: 3 , STOP_TAG: 4 } model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM) optimizer = optim.SGD(model.parameters(), lr=0.01 , weight_decay=1e-4 ) with torch.no_grad(): precheck_sent = prepare_sequence(training_data[0 ][0 ], word_to_ix) precheck_tags = torch.tensor([tag_to_ix[t] for t in training_data[0 ][1 ]], dtype=torch.long) print(model(precheck_sent)) '''(tensor(2.6907), [1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1])''' for epoch in range( 300 ): for sentence, tags in training_data: model.zero_grad() sentence_in = prepare_sequence(sentence, word_to_ix) targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long) loss = model.neg_log_likelihood(sentence_in, targets) loss.backward() optimizer.step() with torch.no_grad(): precheck_sent = prepare_sequence(training_data[0 ][0 ], word_to_ix) print(model(precheck_sent)) ''' (tensor(2.6907), [1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1]) (tensor(20.4906), [0, 1, 1, 1, 2, 2, 2, 0, 1, 2, 2]) '''
以上就是全部内容了,如果有任何疑问和指正,欢迎在下方评论!